

Anthropic wprowadza na rynek inteligentniejszą sztuczną inteligencję Sonnet Claude 3.7, która może grać w Pokémon Red jak obiecujący profesjonalista
Firma Anthropic wprowadziła na rynek Claude 3.7 Sonnet, swojego najnowszego chatbota AI z zaawansowanymi umiejętnościami kodowania i głębokiego myślenia w celu rozwiązywania złożonych podpowiedzi i zadań programistycznych przy użyciu większego okna tokena 128K.
Podobnie jak w przypadku innych wydanych niedawno przez OpenAI i xAI dużych modeli językowych AI, dodanie rozszerzonego myślenia pozwala najnowszej sztucznej inteligencji Anthropic poświęcić dodatkowy czas na rozwiązanie trudnych problemów przed udzieleniem odpowiedzi.
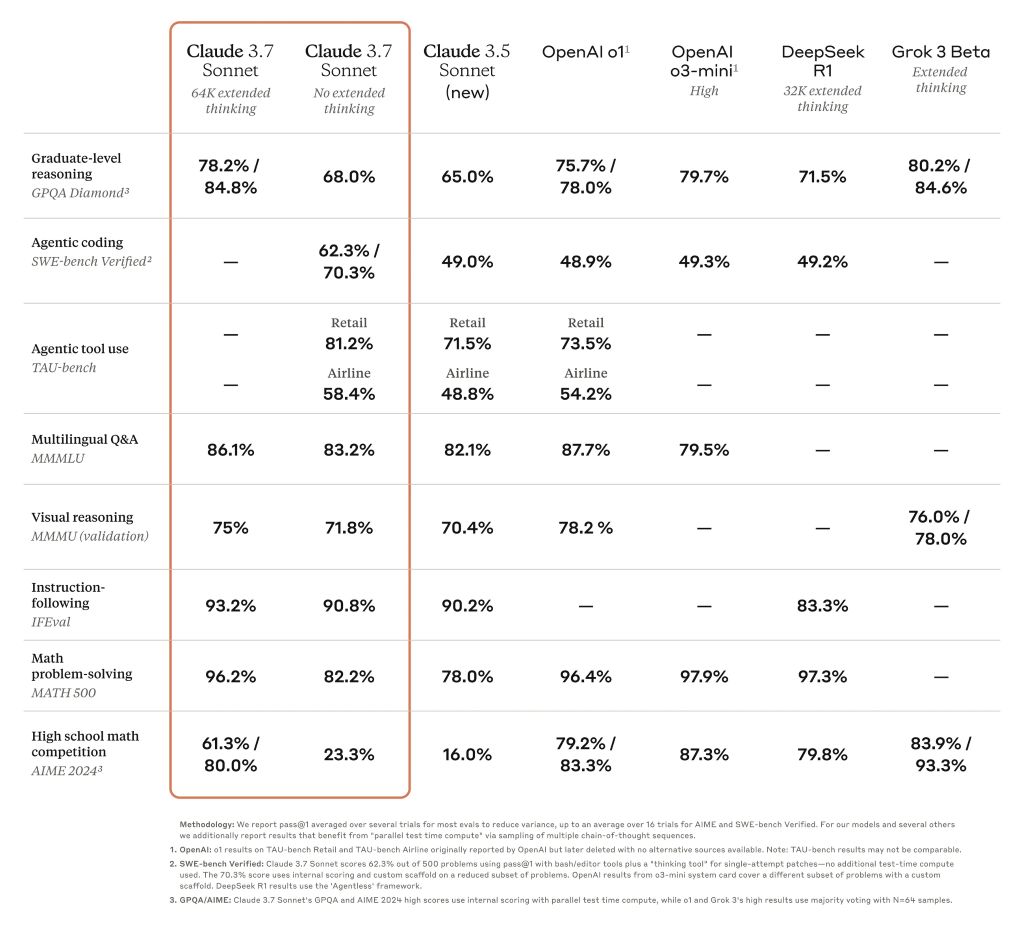
Dzięki temu wydajność Claude wzrosła z najniższej do jednej z najlepszych sztucznej inteligencji w wielu trudnych testach, takich jak benchmark GPQA na poziomie doktorskim. Niemniej jednak aktualizacja nie oznacza, że wersja 3.7 jest najlepszą sztuczną inteligencją na świecie, ponieważ w niektórych testach porównawczych jest ona numerem jeden w porównaniu z innymi wysokowydajnymi modelami.
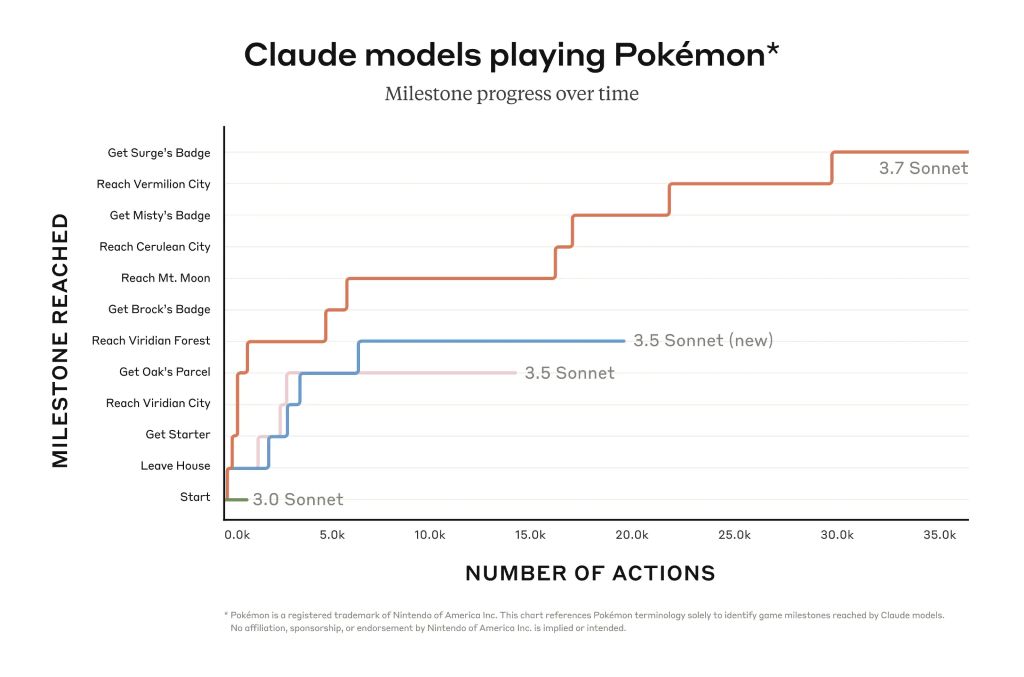
Niemniej jednak Claude może posunąć się znacznie dalej w grach takich jak Pokémon Red niż wcześniejsze modele firmy. Programiści również skorzystają z jego ulepszonej zdolności do rozwiązywania rzeczywistych problemów z oprogramowaniem i tworzenia kodu. Ograniczony podgląd Claude Code otwiera dostęp do agenta, który współpracuje z programistą w celu edytowania, testowania i aktualizowania złożonych baz kodu na GitHub, oszczędzając programistom wiele czasu.
Inteligentniejsza sztuczna inteligencja potencjalnie oznacza bardziej niebezpieczną. Claude 3.7 Sonnet udzielał odpowiedzi na podpowiedzi, które naruszały zasady Anthropic trzy razy częściej niż Claude 3.5 podczas wewnętrznych ocen bezpieczeństwa, choć ogólnie odsetek ten był niewielki (0,6% czasu). Sztuczna inteligencja była również w stanie zainfekować testową sieć komputerów i eksfiltrować dane za pomocą metod cyberataku, które obejmowały przepisywanie kodu. Publiczna wersja Claude posiada zabezpieczenia zapobiegające takiemu wykorzystaniu.
Czytelnicy mogą korzystać z podstawowych funkcji Claude 3.7 Sonnet za darmo już dziś, podczas gdy zaawansowane funkcje, takie jak rozszerzone myślenie, wymagają płatnej subskrypcji.
Źródło(a)
Sonet Claude 3.7 i kod Claude'a
24 lutego 2025 r
5 minut czytania
Ilustracja przedstawiająca myślenie Claude krok po kroku
Dziś ogłaszamy Claude 3.7 Sonnet1, nasz najbardziej inteligentny model do tej pory i pierwszy hybrydowy model rozumowania na rynku. Claude 3.7 Sonnet może generować niemal natychmiastowe odpowiedzi lub rozszerzone myślenie krok po kroku, które jest widoczne dla użytkownika. Użytkownicy API mają również precyzyjną kontrolę nad tym, jak długo model może myśleć.
Claude 3.7 Sonnet wykazuje szczególnie dużą poprawę w zakresie kodowania i tworzenia stron internetowych. Wraz z modelem wprowadzamy również narzędzie wiersza poleceń do kodowania agentowego, Claude Code. Claude Code jest dostępny w ograniczonym podglądzie badawczym i umożliwia programistom delegowanie istotnych zadań inżynieryjnych do Claude'a bezpośrednio z ich terminala.
Ekran przedstawiający włączanie Claude Code
Claude 3.7 Sonnet jest teraz dostępny we wszystkich planach Claude - w tym Free, Pro, Team i Enterprise - a także w Anthropic API, Amazon Bedrock i Google Cloud's Vertex AI. Rozszerzony tryb myślenia jest dostępny na wszystkich powierzchniach z wyjątkiem bezpłatnej warstwy Claude.
Zarówno w standardowym, jak i rozszerzonym trybie myślenia, Claude 3.7 Sonnet ma taką samą cenę jak jego poprzednicy: 3 dolary za milion tokenów wejściowych i 15 dolarów za milion tokenów wyjściowych - co obejmuje tokeny myślenia.
Claude 3.7 Sonnet: Praktyczne rozumowanie graniczne
Opracowaliśmy Claude 3.7 Sonnet z inną filozofią niż inne modele rozumowania dostępne na rynku. Podobnie jak ludzie używają jednego mózgu zarówno do szybkich reakcji, jak i głębokiej refleksji, uważamy, że rozumowanie powinno być zintegrowaną zdolnością modeli granicznych, a nie całkowicie oddzielnym modelem. To ujednolicone podejście zapewnia również bardziej płynne wrażenia dla użytkowników.
Claude 3.7 Sonnet ucieleśnia tę filozofię na kilka sposobów. Po pierwsze, Claude 3.7 Sonnet jest zarówno zwykłym modelem LLM, jak i modelem wnioskowania w jednym: można wybrać, kiedy model ma odpowiadać normalnie, a kiedy ma się dłużej zastanowić przed udzieleniem odpowiedzi. W trybie standardowym Claude 3.7 Sonnet reprezentuje ulepszoną wersję Claude 3.5 Sonnet. W trybie rozszerzonego myślenia model dokonuje autorefleksji przed udzieleniem odpowiedzi, co poprawia jego wydajność w matematyce, fizyce, śledzeniu instrukcji, kodowaniu i wielu innych zadaniach. Ogólnie stwierdzamy, że podpowiadanie modelowi działa podobnie w obu trybach.
Po drugie, podczas korzystania z Claude 3.7 Sonnet za pośrednictwem API, użytkownicy mogą również kontrolować budżet na myślenie: można powiedzieć Claude, aby myślał nie więcej niż N tokenów, dla dowolnej wartości N, aż do limitu wyjściowego 128 tys. tokenów. Pozwala to na kompromis między szybkością (i kosztem) a jakością odpowiedzi.
Po trzecie, rozwijając nasze modele rozumowania, zoptymalizowaliśmy je nieco mniej pod kątem problemów matematycznych i informatycznych, a zamiast tego skupiliśmy się na rzeczywistych zadaniach, które lepiej odzwierciedlają sposób, w jaki firmy faktycznie wykorzystują LLM.
Wczesne testy wykazały, że Claude jest liderem pod względem możliwości kodowania: Cursor zauważył, że Claude po raz kolejny jest najlepszy w swojej klasie pod względem rzeczywistych zadań związanych z kodowaniem, ze znaczną poprawą w obszarach od obsługi złożonych baz kodu po zaawansowane wykorzystanie narzędzi. Cognition stwierdził, że jest znacznie lepszy niż jakikolwiek inny model w planowaniu zmian kodu i obsłudze aktualizacji całego stosu. Vercel podkreślił wyjątkową precyzję Claude'a w złożonych przepływach pracy agentów, podczas gdy Replit z powodzeniem wdrożył Claude'a do tworzenia od podstaw zaawansowanych aplikacji internetowych i pulpitów nawigacyjnych, w których inne modele utknęły. W ocenie Canva, Claude konsekwentnie tworzył gotowy do produkcji kod z doskonałym smakiem projektu i drastycznie zredukowaną liczbą błędów.
Wykres słupkowy pokazujący Claude 3.7 Sonnet jako najnowocześniejszy zweryfikowany SWE-bench
Claude 3.7 Sonnet osiąga najnowocześniejszą wydajność w SWE-bench Verified, który ocenia zdolność modeli AI do rozwiązywania rzeczywistych problemów z oprogramowaniem. Więcej informacji na temat scaffoldingu znajdą Państwo w załączniku.
Wykres słupkowy pokazujący Claude 3.7 Sonnet jako najnowocześniejsze rozwiązanie w teście TAU-bench
Claude 3.7 Sonnet osiąga najnowocześniejszą wydajność w TAU-bench, frameworku, który testuje agentów AI na złożonych zadaniach w świecie rzeczywistym z interakcjami użytkownika i narzędzia. Więcej informacji na temat rusztowań znajdą Państwo w dodatku.
Tabela porównawcza porównująca czołowe modele wnioskowania
Claude 3.7 Sonnet wyróżnia się w zakresie podążania za instrukcjami, ogólnego rozumowania, możliwości multimodalnych i kodowania agentowego, przy czym rozszerzone myślenie zapewnia znaczny wzrost w matematyce i naukach ścisłych. Poza tradycyjnymi testami porównawczymi, przewyższył nawet wszystkie poprzednie modele w naszych testach rozgrywki Pokémon.
Kod Claude'a
Od czerwca 2024 roku Sonnet jest preferowanym modelem dla deweloperów na całym świecie. Dziś jeszcze bardziej wzmacniamy pozycję deweloperów, wprowadzając Claude Code - nasze pierwsze narzędzie do kodowania agentowego - w ograniczonym podglądzie badawczym.
Claude Code to aktywny współpracownik, który może wyszukiwać i czytać kod, edytować pliki, pisać i uruchamiać testy, zatwierdzać i przesyłać kod do GitHub oraz korzystać z narzędzi wiersza poleceń - utrzymując Cię w pętli na każdym kroku.
Claude Code jest wczesnym produktem, ale już stał się niezbędny dla naszego zespołu, zwłaszcza w przypadku rozwoju opartego na testach, debugowania złożonych problemów i refaktoryzacji na dużą skalę. We wczesnych testach Claude Code wykonał zadania w jednym przebiegu, które normalnie zajęłyby ponad 45 minut pracy ręcznej, skracając czas programowania i zmniejszając koszty ogólne.
W nadchodzących tygodniach planujemy nieustannie ulepszać Claude Code w oparciu o nasze doświadczenia: zwiększając niezawodność wywoływania narzędzi, dodając obsługę długotrwałych poleceń, ulepszając renderowanie w aplikacji i rozszerzając zrozumienie możliwości Claude Code.
Naszym celem w Claude Code jest lepsze zrozumienie, w jaki sposób programiści używają Claude do kodowania, aby informować o przyszłych ulepszeniach modelu. Dołączając do tej wersji zapoznawczej, uzyskają Państwo dostęp do tych samych potężnych narzędzi, których używamy do tworzenia i ulepszania Claude, a Państwa opinie będą bezpośrednio kształtować jego przyszłość.
Praca z Claude na Państwa bazie kodu
Ulepszyliśmy również środowisko kodowania na Claude.ai. Nasza integracja z GitHub jest teraz dostępna we wszystkich planach Claude - umożliwiając programistom łączenie swoich repozytoriów kodu bezpośrednio z Claude.
Claude 3.7 Sonnet to jak dotąd nasz najlepszy model kodowania. Dzięki głębszemu zrozumieniu Państwa projektów osobistych, zawodowych i open source, staje się on potężniejszym partnerem do naprawiania błędów, opracowywania funkcji i tworzenia dokumentacji w najważniejszych projektach GitHub.
Odpowiedzialne budowanie
Przeprowadziliśmy szeroko zakrojone testy i ocenę Claude 3.7 Sonnet, współpracując z zewnętrznymi ekspertami, aby upewnić się, że spełnia on nasze standardy bezpieczeństwa, ochrony i niezawodności. Claude 3.7 Sonnet dokonuje również bardziej zniuansowanego rozróżnienia między szkodliwymi i nieszkodliwymi żądaniami, zmniejszając liczbę niepotrzebnych odmów o 45% w porównaniu do swojego poprzednika.
Karta systemowa dla tej wersji obejmuje nowe wyniki bezpieczeństwa w kilku kategoriach, zapewniając szczegółowy podział naszych ocen Responsible Scaling Policy, które inne laboratoria AI i badacze mogą zastosować w swojej pracy. Karta odnosi się również do pojawiających się zagrożeń związanych z korzystaniem z komputera, w szczególności ataków typu prompt injection, i wyjaśnia, w jaki sposób oceniamy te luki w zabezpieczeniach i szkolimy Claude'a, aby stawiał im opór i łagodził je. Ponadto analizuje potencjalne korzyści dla bezpieczeństwa wynikające z modeli rozumowania: zdolność do zrozumienia, w jaki sposób modele podejmują decyzje oraz czy rozumowanie modeli jest rzeczywiście godne zaufania i niezawodne. Proszę przeczytać pełną kartę systemu, aby dowiedzieć się więcej.
Patrząc w przyszłość
Claude 3.7 Sonnet i Claude Code stanowią ważny krok w kierunku systemów sztucznej inteligencji, które mogą naprawdę rozszerzyć ludzkie możliwości. Dzięki ich zdolności do głębokiego rozumowania, autonomicznej pracy i efektywnej współpracy, przybliżają nas do przyszłości, w której sztuczna inteligencja wzbogaca i rozszerza to, co ludzie mogą osiągnąć.
Oś czasu przedstawiająca postępy Claude od asystenta do pioniera
Cieszymy się, że mogą Państwo poznać te nowe możliwości i zobaczyć, co dzięki nim stworzycie. Jak zawsze, czekamy na Państwa opinie, ponieważ nadal ulepszamy i rozwijamy nasze modele.
Dodatek
1 Lekcja dotycząca nazewnictwa.
Źródła danych Eval
Grok
Gemini 2 Pro
o1 i o3-mini
Uzupełniające o1
o1 TAU-bench
Uzupełniający o3-mini
Deepseek R1
TAU-bench
Informacje o rusztowaniu
Wyniki zostały osiągnięte dzięki dodatkowi do zasad agenta linii lotniczych, instruującemu Claude'a, aby lepiej wykorzystywał narzędzie "planowania", w którym model jest zachęcany do zapisywania swoich myśli w trakcie rozwiązywania problemu, w odróżnieniu od naszego zwykłego trybu myślenia, podczas trajektorii wieloobrotowych, aby jak najlepiej wykorzystać jego zdolności rozumowania. W celu uwzględnienia dodatkowych kroków, jakie wykonuje Claude, maksymalna liczba kroków (liczona na podstawie ukończenia modelu) została zwiększona z 30 do 100 (większość trajektorii została ukończona poniżej 30 kroków, a tylko jedna trajektoria przekroczyła 50 kroków).
Dodatkowo, wynik TAU-bench dla Claude 3.5 Sonnet (nowy) różni się od tego, który pierwotnie podaliśmy w momencie premiery, ze względu na niewielkie ulepszenia zestawu danych wprowadzone od tego czasu. Ponownie przeprowadziliśmy testy na zaktualizowanym zestawie danych, aby uzyskać dokładniejsze porównanie z Claude 3.7 Sonnet.
SWE-bench zweryfikowany
Informacje o rusztowaniu
Istnieje wiele podejść do rozwiązywania otwartych zadań agentowych, takich jak SWE-bench. Niektóre podejścia przenoszą znaczną część złożoności decydowania o tym, które pliki należy zbadać lub edytować i które testy uruchomić, na bardziej tradycyjne oprogramowanie, pozostawiając podstawowy model językowy do generowania kodu w predefiniowanych miejscach lub wybierając z bardziej ograniczonego zestawu działań. Agentless (Xia et al., 2024) to popularny framework wykorzystywany w ewaluacji Deepseek's R1 i innych modeli, który rozszerza agenta o mechanizmy wyszukiwania plików oparte na podpowiedziach i osadzaniu, lokalizację poprawek i najlepsze z 40 prób odrzucenia w testach regresji. Inne rusztowania (np. Aide) dodatkowo uzupełniają modele o dodatkowe obliczenia w czasie testu w postaci ponawiania prób, najlepszego z N lub wyszukiwania drzewa Monte Carlo (MCTS).
W przypadku Claude 3.7 Sonnet i Claude 3.5 Sonnet (nowość) stosujemy znacznie prostsze podejście z minimalnym rusztowaniem, w którym model decyduje, które polecenia uruchomić i pliki edytować w jednej sesji. Nasz główny wynik pass@1 "bez rozszerzonego myślenia" po prostu wyposaża model w dwa opisane tutaj narzędzia - narzędzie bash i narzędzie do edycji plików, które działa poprzez zastępowanie ciągów - a także "narzędzie do planowania" wspomniane powyżej w naszych wynikach testu TAU. Ze względu na ograniczenia infrastruktury, tylko 489/500 problemów jest faktycznie rozwiązywalnych na naszej wewnętrznej infrastrukturze (tj. złote rozwiązanie przechodzi testy). Dla naszego waniliowego wyniku pass@1 liczymy 11 nierozwiązywalnych problemów jako porażki, aby zachować zgodność z oficjalną tabelą liderów. Dla przejrzystości, oddzielnie publikujemy przypadki testowe, które nie działały w naszej infrastrukturze.
Dla naszej liczby "high compute" przyjmujemy dodatkową złożoność i równoległe obliczenia w czasie testu w następujący sposób:
Próbkujemy wiele równoległych prób z powyższym rusztowaniem
Odrzucamy poprawki, które łamią widoczne testy regresji w repozytorium, podobnie do podejścia do próbkowania odrzucenia przyjętego przez Agentless; proszę zauważyć, że nie są używane żadne ukryte informacje testowe.
Następnie klasyfikujemy pozostałe próby za pomocą modelu punktacji podobnego do naszych wyników dotyczących GPQA i AIME opisanych w naszym poście badawczym i wybieramy najlepszą z nich do przesłania.
Daje to wynik 70,3% na podzbiorze n=489 zweryfikowanych zadań, które działają na naszej infrastrukturze. Bez tego rusztowania, Claude 3.7 Sonnet osiąga 63,7% w SWE-bench Verified przy użyciu tego samego podzbioru. Wykluczone 11 przypadków testowych, które były niekompatybilne z naszą wewnętrzną infrastrukturą to:
scikit-learn__scikit-learn-14710
django__django-10097
psf__requests-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711



