

Dogłębna analiza architektury AMD RDNA 4: Monolityczna konstrukcja 64-CU z wszechstronnymi ulepszeniami w zakresie obliczeń, kodowania i dekodowania multimediów, ray tracingu i sztucznej inteligencji

AMD zaoferowało sneak peek rDNA 4 na targach CES 2025 i potwierdziło pojawienie się kart Radeon RX 9070 XT i RX 9070, ale nie zaoferowało nawet przelotnej uwagi na temat nowej architektury podczas faktycznego keynote.
Firma utrzymywała jednak, że więcej informacji na temat RDNA 4 i nowych procesorów graficznych Radeon pojawi się wkrótce i oto jesteśmy.
Dziś AMD ujawnia RDNA 4 i nowe procesory graficzne z serii Radeon RX 9070. Seria RX 9070 będzie oficjalnie dostępna w sklepach detalicznych od 6 marca, a recenzje wydajności pojawią się dzień wcześniej.
AMD RDNA 4: Powrót do monolitycznej konstrukcji
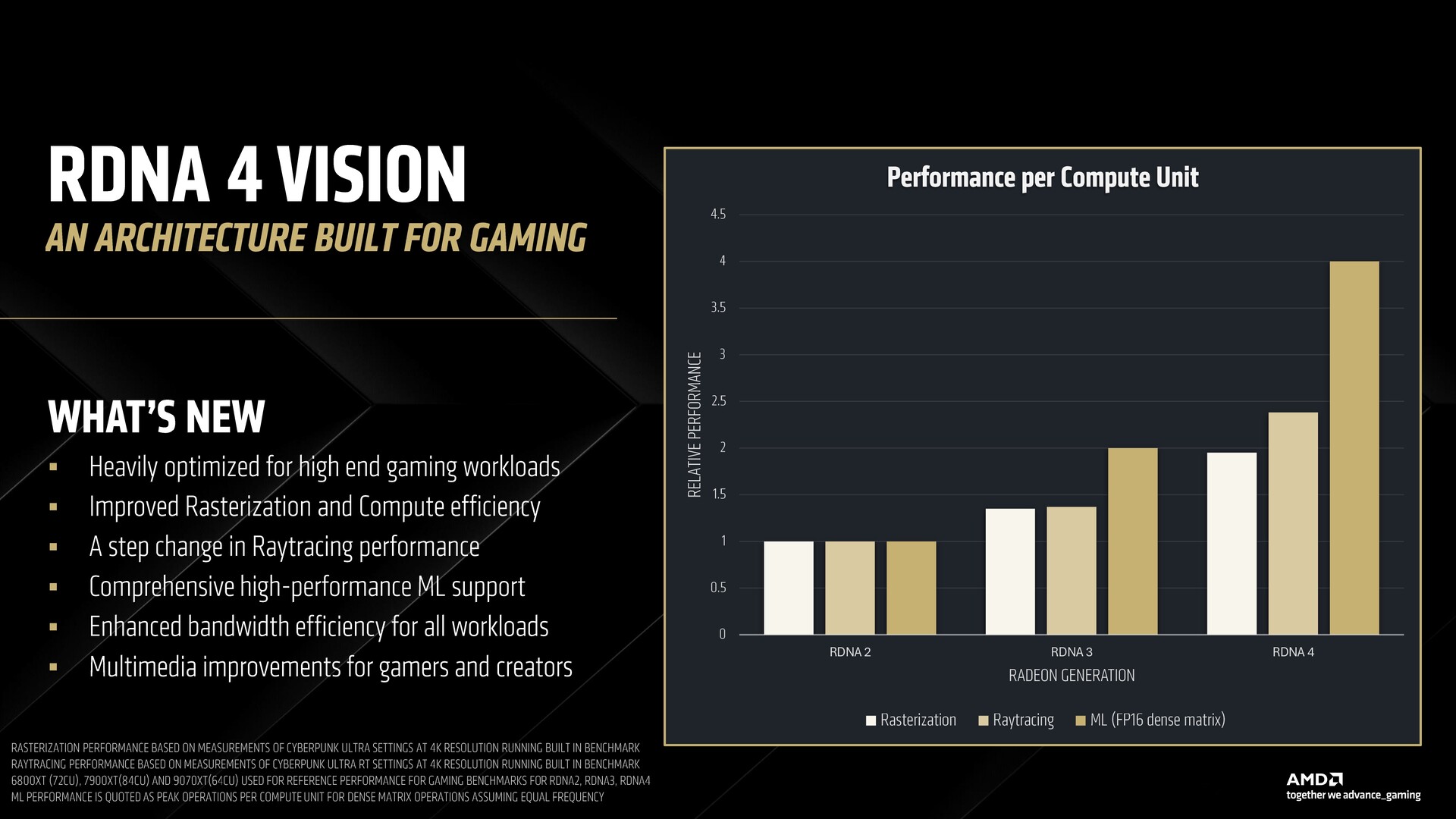
RDNA 4 opiera się na celach, które AMD wyznaczyło sobie w RDNA 3. Według AMD, RDNA 4 został zaprojektowany z myślą o cięższych obciążeniach w grach, z naciskiem na lepszą wydajność i efektywność rasteryzacji.
Następnie wprowadzono zwyczajowe ulepszenia potoków ray tracingu, a także ponownie skupiono się na możliwościach sztucznej inteligencji i kodowaniu/dekodowaniu multimediów.
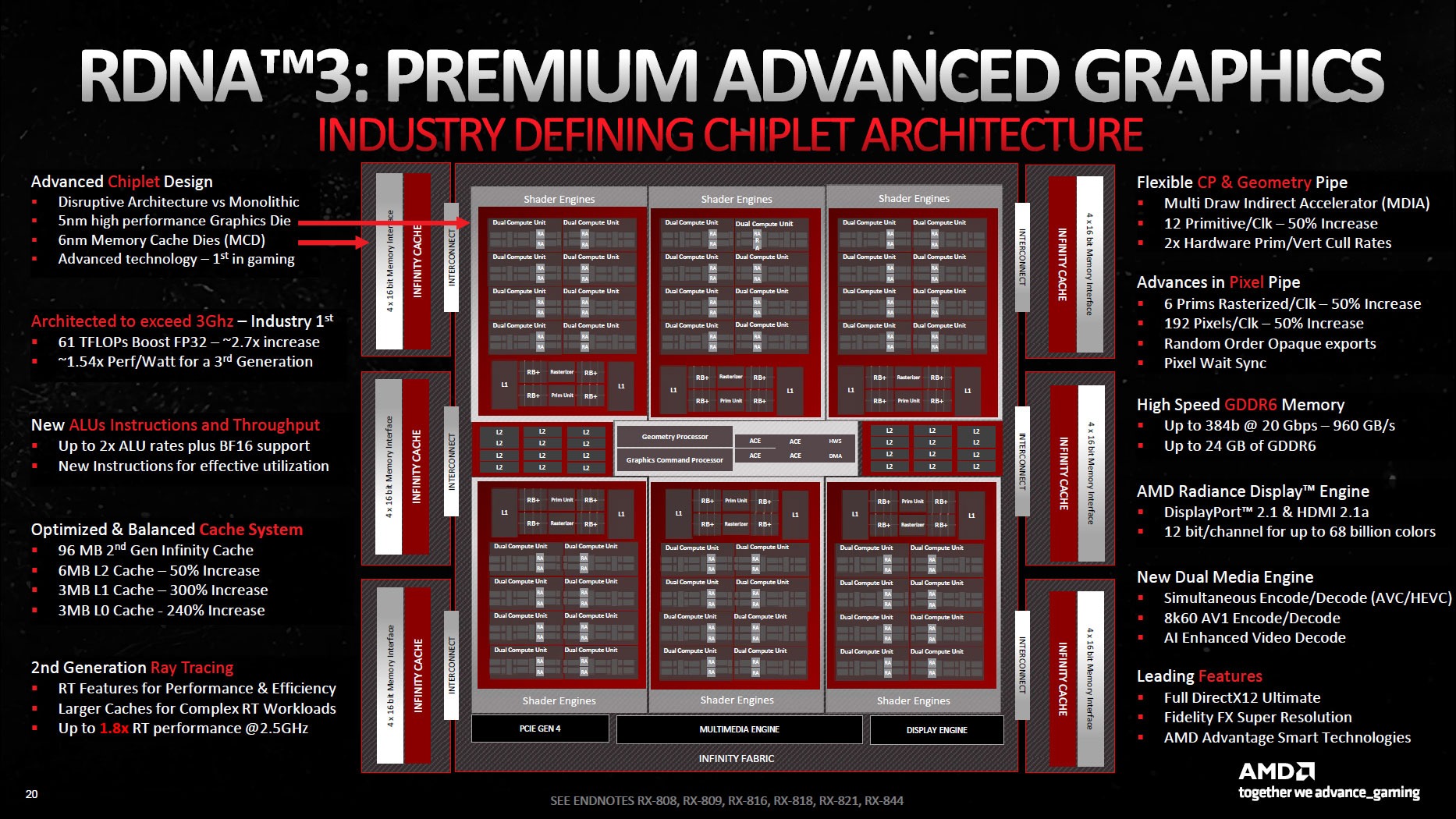
W RDNA 3 pojawiła się konstrukcja chipletowa dla układów GPU, czerpiąca inspirację z procesorów Ryzen. Widzieliśmy tutaj oddzielenie matryc pamięci podręcznej (MCD) od matrycy obliczeniowej grafiki (GCD).
W przypadku RDNA 4, AMD powraca jednak do tradycyjnej monolitycznej konstrukcji. Komponenty są zasadniczo takie same, ale nie ma połączeń MCD-GCD, ponieważ pamięć i obliczenia są teraz bezpośrednio połączone przez Infinity Cache.
Procesor graficzny RDNA 4, w tym przypadku Radeon RX 9070 XT, zawiera cztery silniki cieniujące z ośmioma procesorami grup roboczych (WGP) każdy. Każdy WGP składa się z ośmiu jednostek obliczeniowych (CU), co daje łącznie 64 CU.
AMD twierdzi, że nowe jednostki obliczeniowe są teraz bardziej wydajne niż kiedykolwiek, umożliwiając ulepszony ray tracing, podwojenie szczytowej przepustowości, obsługę najnowszych możliwości akceleracji macierzy z szerszą obsługą formatów numerycznych.
Nowością w RDNA 4 CU, którą widzieliśmy już w rdzeniach Tensor w architekturze Ampere firmy Nvidia, jest obsługa strukturalnej rzadkości, która pozwala na szybsze operacje na macierzach, zwłaszcza w przypadkach, gdy wiele wag wynosi zero.
Widzimy również ulepszenia w podsystemie pamięci. Pamięć podręczna L2 została zwiększona z 6 MB w RDNA 3 do 8 MB w RDNA 4, podczas gdy pamięć podręczna Infinity została ulepszona do 3. generacji, ale spadła do 64 MB z 96 MB w RDNA 3.
AMD nadal polega na pamięci GDDR6 w nowej generacji. Zarówno RX 9070 XT, jak i RX 9070 oferują 384-bitowy interfejs pamięci GDDR6 o pojemności 16 GB taktowany zegarem 20 Gb/s, co daje efektywną przepustowość 640 GB/s. Jest to znacznie mniej niż przepustowość 960 GB/s oferowana przez RDNA 3, ale AMD twierdzi, że specyfikacje pamięci wideo RDNA 4 zostały starannie dobrane, aby obsługiwać obecne i przyszłe tytuły.
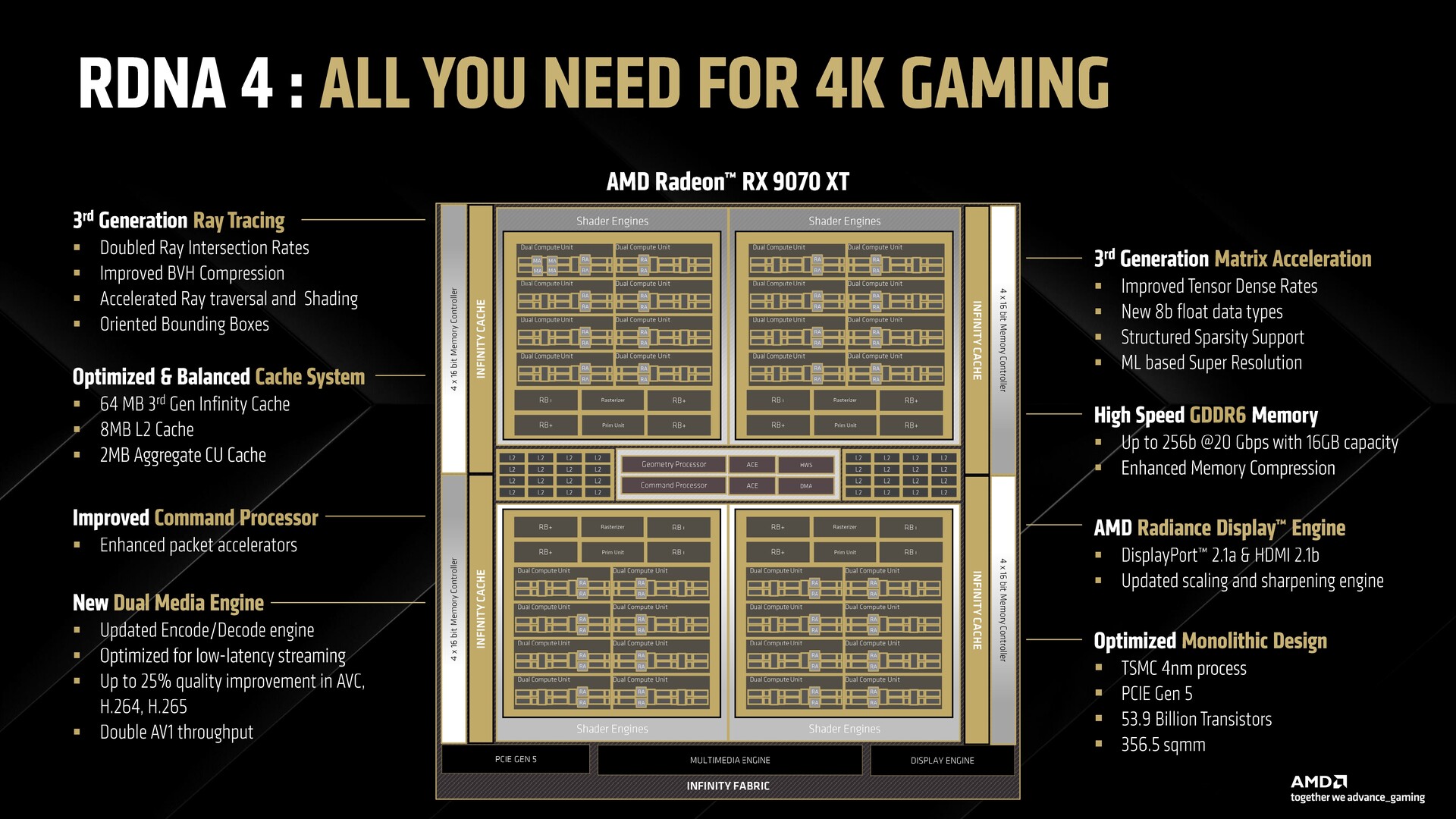
Ulepszony silnik multimediów i obsługa sprzętowego pomiaru przerzucania
Kodowanie wideo było jedną z głównych pułapek RDNA 3, a AMD obiecuje znaczną poprawę w tym zakresie. Firma obiecuje znaczne ulepszenia w kodowaniu H.264 i AV1 oraz mniej blokujących artefaktów przy tej samej ilości danych.
Ulepszenia dotyczą również dekodowania wideo, ze zmniejszonym zużyciem energii i zwiększoną wydajnością podczas dekodowania formatów takich jak AV1 i VP9.
Radiance Display Engine zużywa teraz znacznie mniej energii w dwumonitorowych konfiguracjach FreeSync. Nowością jest również obsługa sprzętowej kolejki przerzucania w Windows Display Driver Model (WDDM) 3.0 dla odtwarzania wideo.
Zwalnia to zasoby CPU poprzez odciążenie układu GPU od planowania klatek. Technologia generowania wielu klatek (MFG) w układach GPU Nvidia Blackwell również opiera się na sprzętowym pomiarze klatek.


Spojrzenie na jednostkę obliczeniową RDNA 4
Na początku struktura RDNA 4 CU nie różni się zbytnio od tego, co widzieliśmy w RDNA 3. Istnieją jednak ulepszenia wydajności i efektywności w każdym z komponentów CU.
Operacje WMMA (Wave Matrix Multiply Accumulate) zostały ulepszone, aby spełnić wymagania nowego sprzętu. Jednostki skalujące otrzymały ulepszenia do obsługi operacji Float32. Harmonogram może dzielić i przetwarzać duże obciążenie obliczeniowe na podzielone i nazwane bariery.
AMD stwierdziło, że RDNA 4 został zbudowany z myślą o nowych technikach renderowania, których deweloperzy używają w dzisiejszych grach. Podczas gdy skalowanie w górę było w modzie, efektywne śledzenie ścieżek wymaga akceleracji ML jako części samego procesu renderowania, a nie jako refleksji.
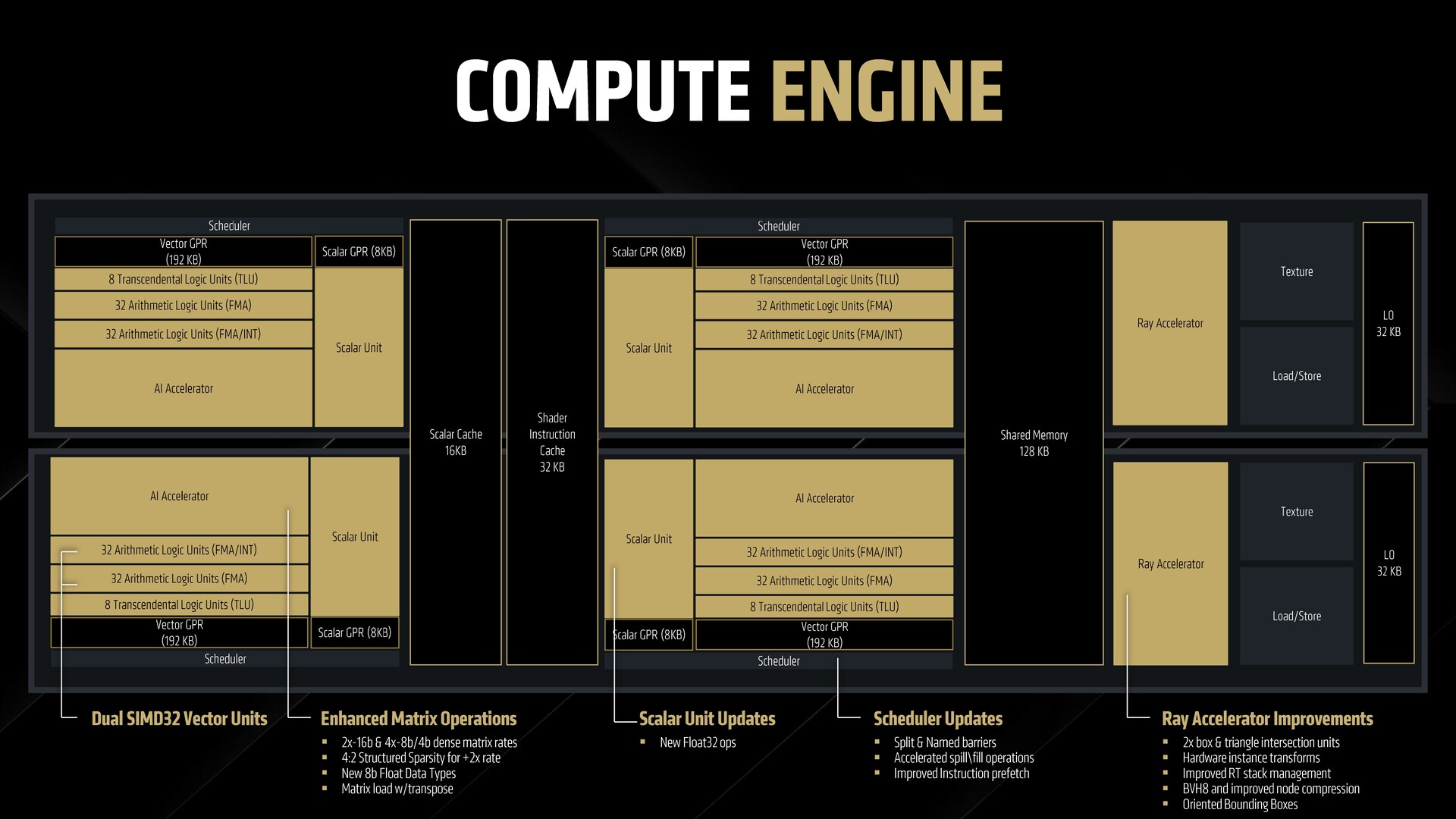

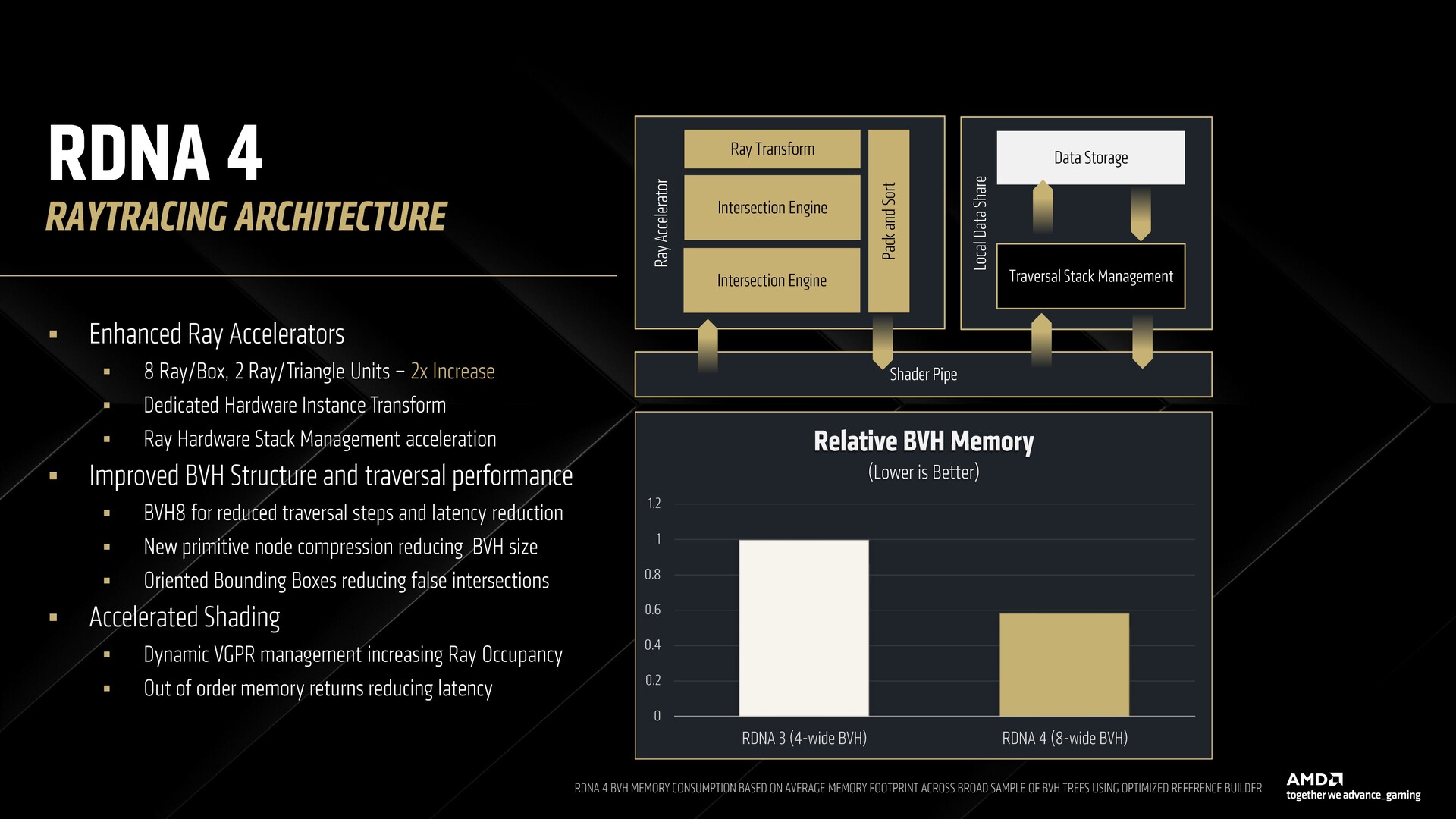
Akceleratory promieniowania w RDNA 4
RDNA 4 oferuje 64 akceleratory promieni trzeciej generacji w RX 9070 XT. Struktura akceleratora promieni w RDNA 4 jest podobna do tej w RDNA 3, ale zawiera dodatkowy silnik przecinania dla 2x większej liczby jednostek ray box i ray triangle.
Istnieje również dedykowana sprzętowa transformacja promieni, która eliminuje potrzebę korzystania z instrukcji cieniowania, minimalizując w ten sposób narzut związany z przechodzeniem promieni. Pamięć 128 KB w każdej podwójnej jednostce CU pomaga przechowywać stos promieni dla wydajnych operacji wypychania i sortowania.
RDNA 4 wprowadza koncepcję zorientowanych ramek ograniczających (OBB), które wyrównują ramki ograniczające BVH do geometrii, minimalizując w ten sposób fałszywie dodatnie interakcje promieni w tym, co w przeciwnym razie jest tylko pustą przestrzenią w pudełku. AMD twierdzi, że takie podejście może poprawić wydajność przechodzenia promieni nawet o 10%.
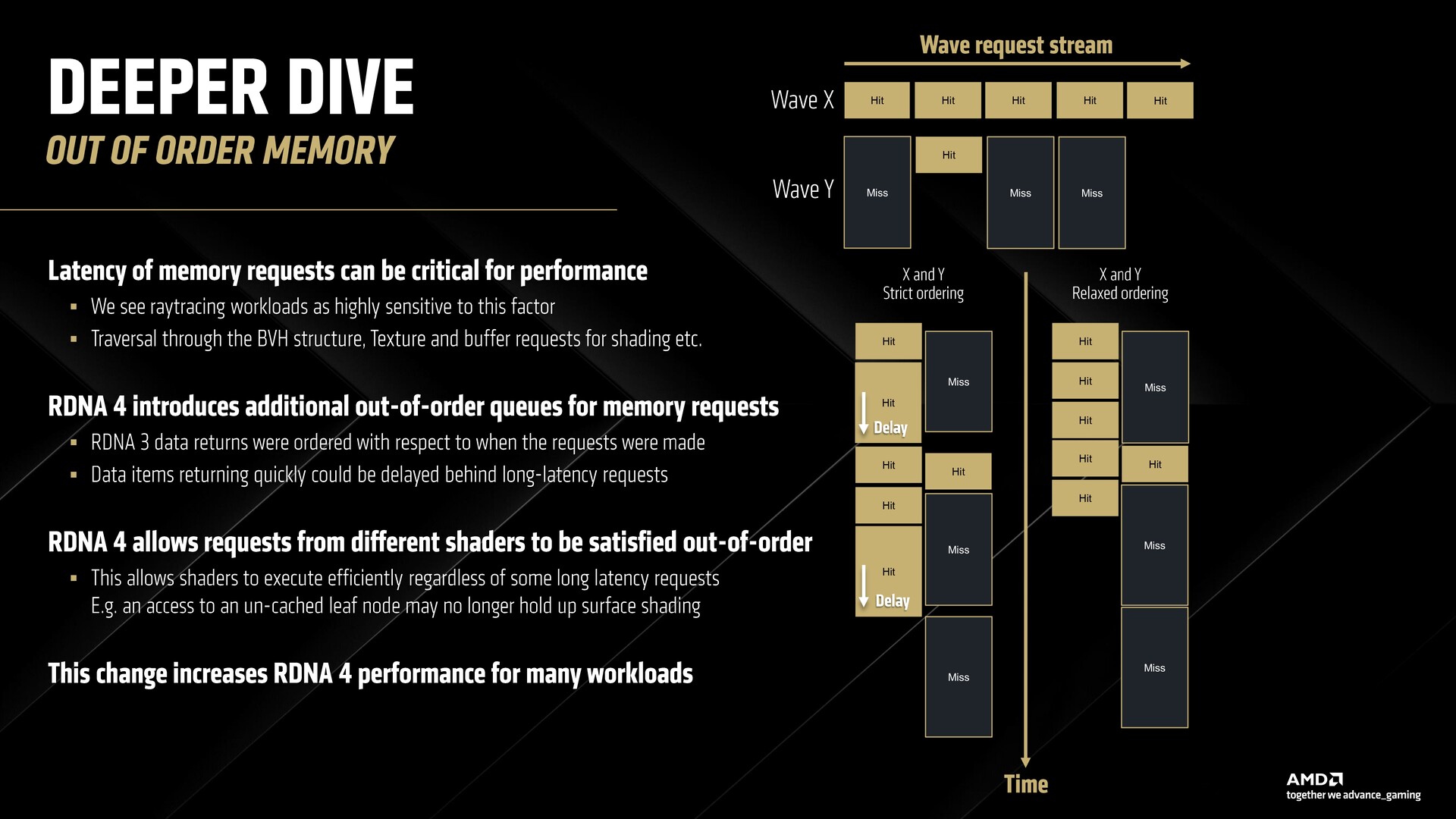
Nowością jest również obsługa zrelaksowanych żądań pamięci poza kolejnością, która skutecznie skraca czas oczekiwania na fale, które nie trafiły wcześniej do pamięci podręcznej wysokiego poziomu. Usprawnia to nie tylko ray tracing, ale także inne obciążenia.
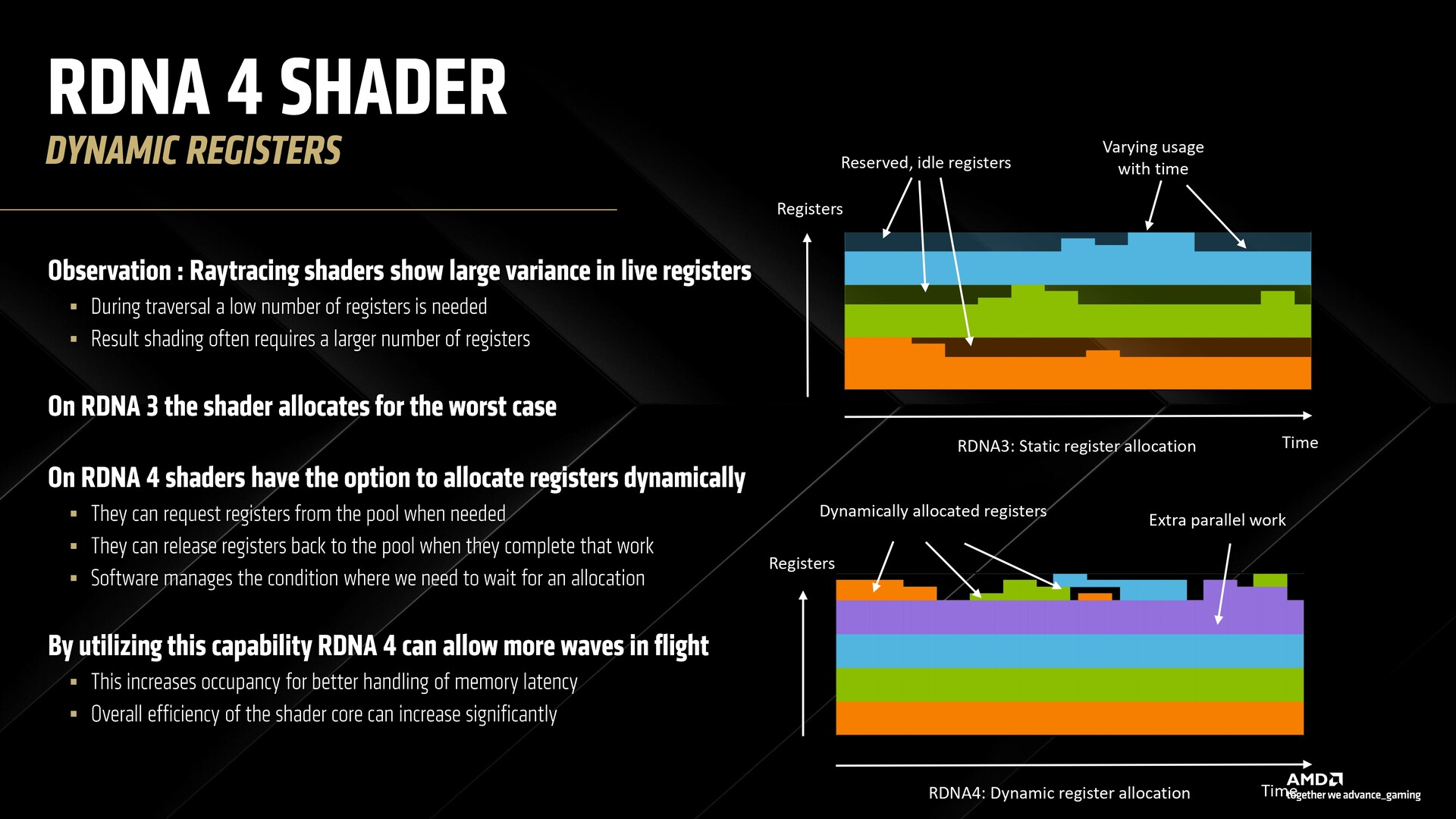
W RDNA 4 shadery mogą dynamicznie alokować rejestry, co pozwala pomieścić więcej fal w locie z poprawionym opóźnieniem pamięci.


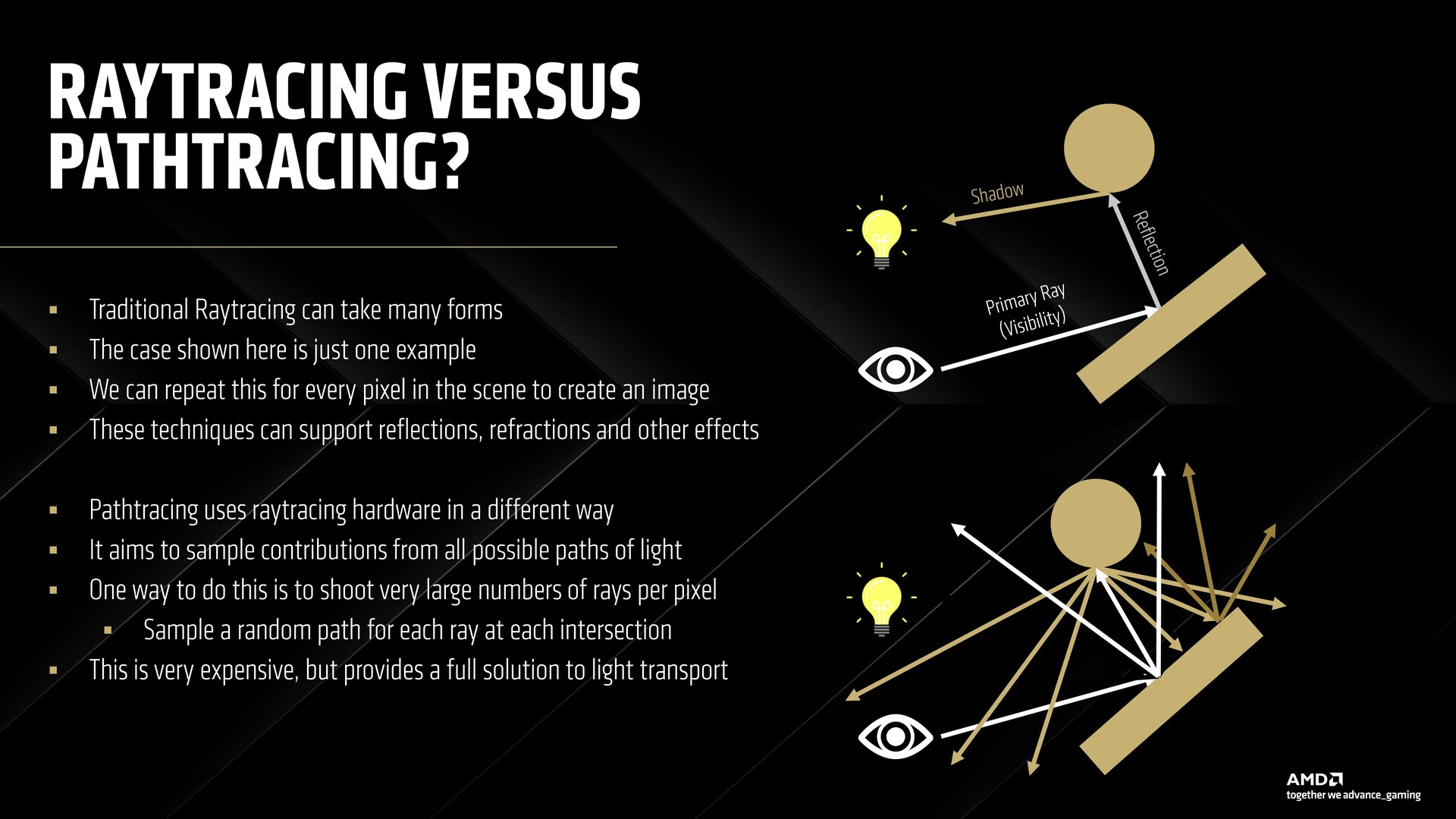
Śledzenie ścieżki z RDNA 4
Karty AMD ogólnie zmagały się z ray tracingiem, więc śledzenie ścieżek wydawało się wykluczone nawet w przypadku topowych kart RDNA 3. RDNA 4 ma to zmienić dzięki obsłudze neuronowego buforowania promieniowania wraz z nowym neuronowym supersamplingiem i modelem denoisingu.
Firma AMD nie podała dokładnych danych dotyczących wydajności w tytułach obsługujących śledzenie ścieżek, ale powinniśmy mieć o tym pojęcie podczas recenzowania tych kart.




Możliwości sztucznej inteligencji oparte na układach Radeon i Instinct
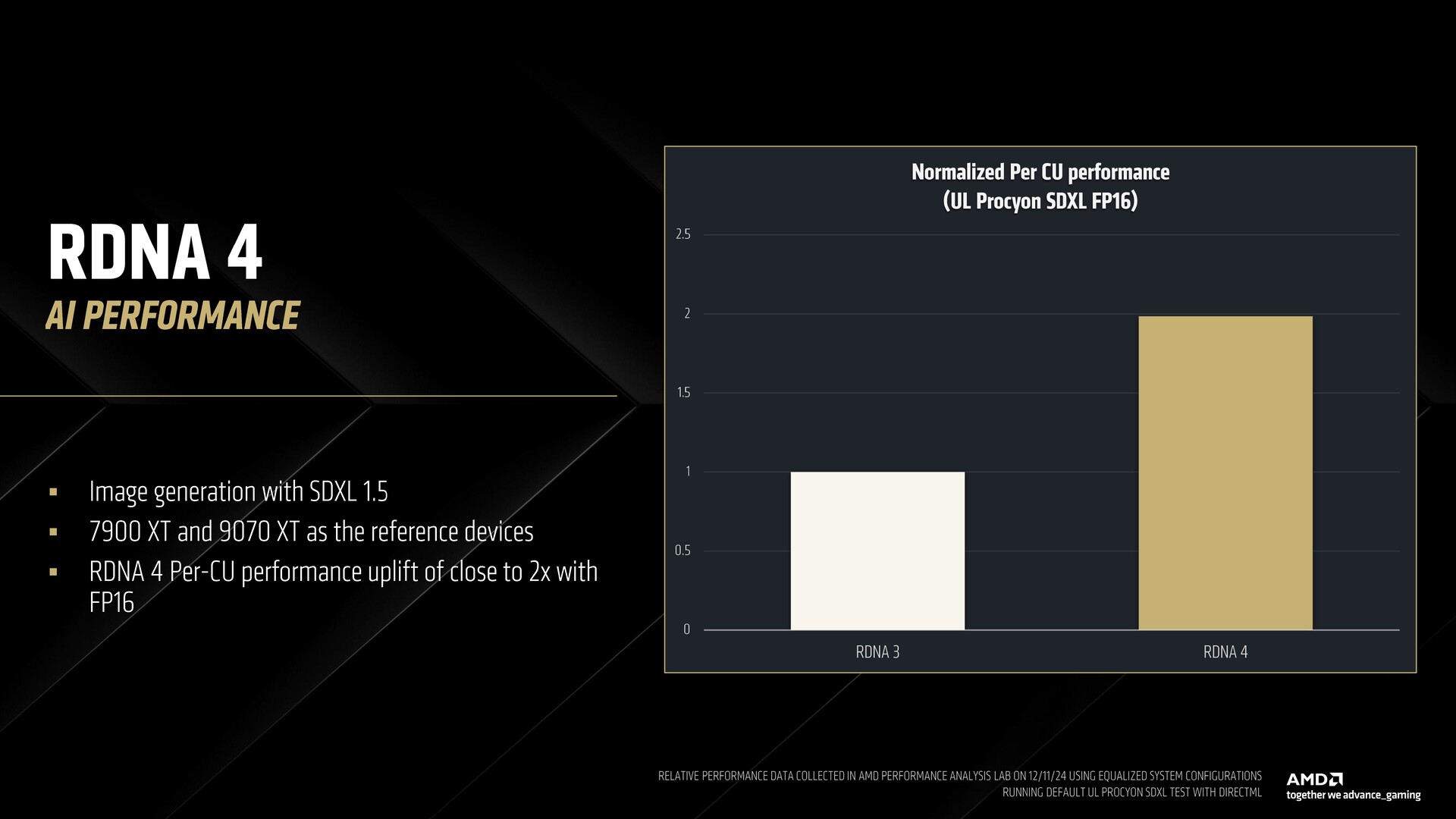
AMD poinformowało, że RDNA 4 oferuje dedykowane potoki matematyczne do akceleracji ML skoncentrowane na wysokiej wydajności z węższymi typami danych. Nowością w RDNA 4 jest obsługa FP8 i BF8 dla wysokiej wydajności i precyzji wnioskowania.
Demonstrując generowanie obrazu SDXL 1.5, AMD pokazało, jak Radeon RX 9070 XT oparty na RDNA 4 oferuje dwukrotnie wyższą wydajność FP16 na jednostkę CU w porównaniu do RX 7900 XT opartego na RDNA 3.
Wykorzystując nowe możliwości sztucznej inteligencji RDNA 4, FSR 4 jest kompleksowym potokiem wyszkolonym na procesorach graficznych AMD. FSR 4 wykorzystuje FP8 w celu optymalnego wykorzystania przepustowości, wydajności i mocy.
AMD wykazało nawet 3,7-krotną poprawę liczby klatek na sekundę dzięki FSR 4 w połączeniu z interpolacją klatek i Radeon Anti-Lag przy zachowaniu wysokiej jakości obrazu.



Źródło(a)
Komunikat prasowy AMD











