

Computex 2024 | Intel Lunar Lake debiutuje jako "najbardziej wydajna" konstrukcja x86 z połączoną wydajnością 120 TOPS AI

Bitwa o prymat w dziedzinie sztucznej inteligencji dopiero zaczyna się rozgrzewać. Intel, ze swoją nową architekturą Lunar Lake, będzie walczył o Państwa ciężko zarobione pieniądze z Qualcomm Snapdragon X Elite / X Plus ARM SoCs, oraz AMD Strix Point Zen 5 Ryzen AI z serii 300 APU w tym, jak twierdzi, najbardziej wydajnym jak dotąd projekcie x86.
Pod koniec zeszłego miesiąca Intel rzucił klucz w prace Qualcomm, ogłaszając nadejście procesorów Lunar Lake dla urządzeń mobilnych z obietnicą łącznej wydajności 100 TOPS AI.
Na targach Computex 2024 Intel szczegółowo opisuje niektóre z soczystych rzeczy, które trafiają do wnętrzności Lunar Lake. Firma nie ogłosiła dokładnych jednostek SKU ani ich indywidualnych konfiguracji, ale w sklepie jest wiele, a ulepszenia w stosunku do Meteor Lake wydają się być dość znaczące, przynajmniej na papierze.

Lunar Lake: Przegląd platformy
Lunar Lake nadal opiera się na technologii pakowania 3D Foveros firmy Intel, która organizuje różne funkcjonujące jednostki na chipie w kafelki, z których głównymi są kafelek obliczeniowy i kafelek kontrolera platformy.
Lunar Lake to pierwszy projekt, który został zlecony zewnętrznej fabryce, zamiast być wykuwany we własnych odlewniach Intela. Intel nadal nie wspomina wyraźnie o węźle produkcyjnym w swoich materiałach, ale CEO Pat Gelsinger wskazał niedawno, że procesor Lunar Lake, GPU i NPU są wytwarzane w TSMC N3B.
Zastosowanie bardziej kompaktowego opakowania Foveros 2.5D oznacza, że do przeniesienia danych z matrycy do pamięci RAM potrzeba mniej energii. Umożliwia to Intelowi bezpośrednią integrację pamięci DRAM z samym opakowaniem. Według Intela, Lunar Lake może oferować do 32 GB pamięci LPDDR5X-8500 dual-rank na matrycy.


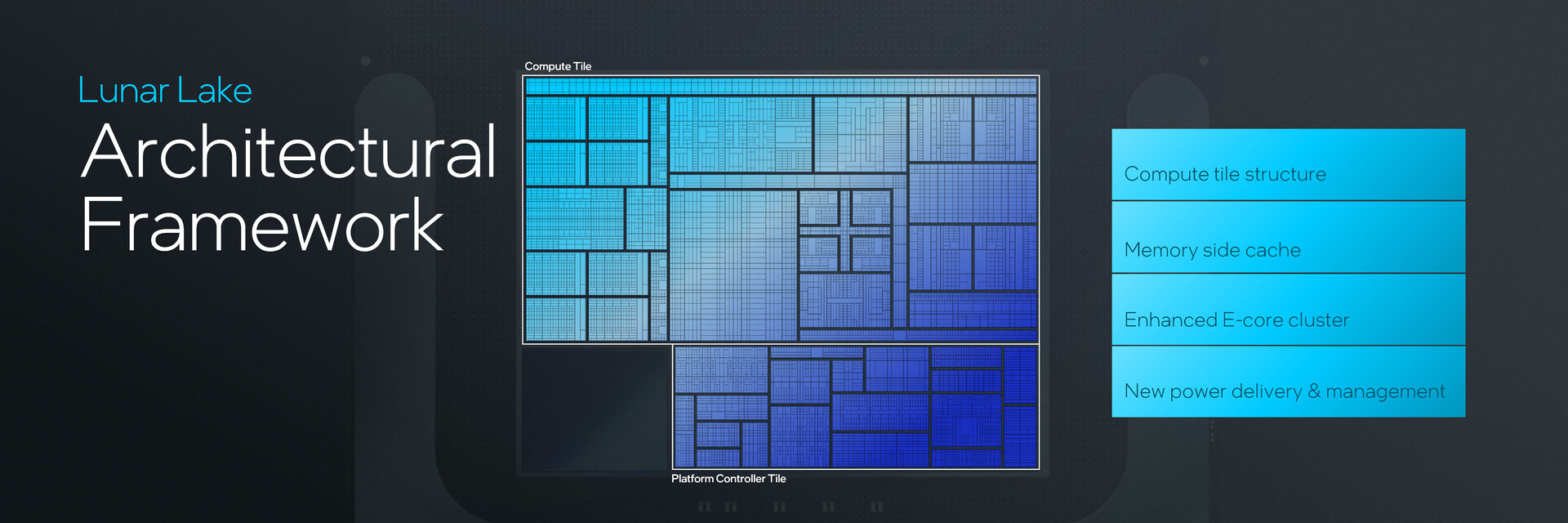
Płytka obliczeniowa
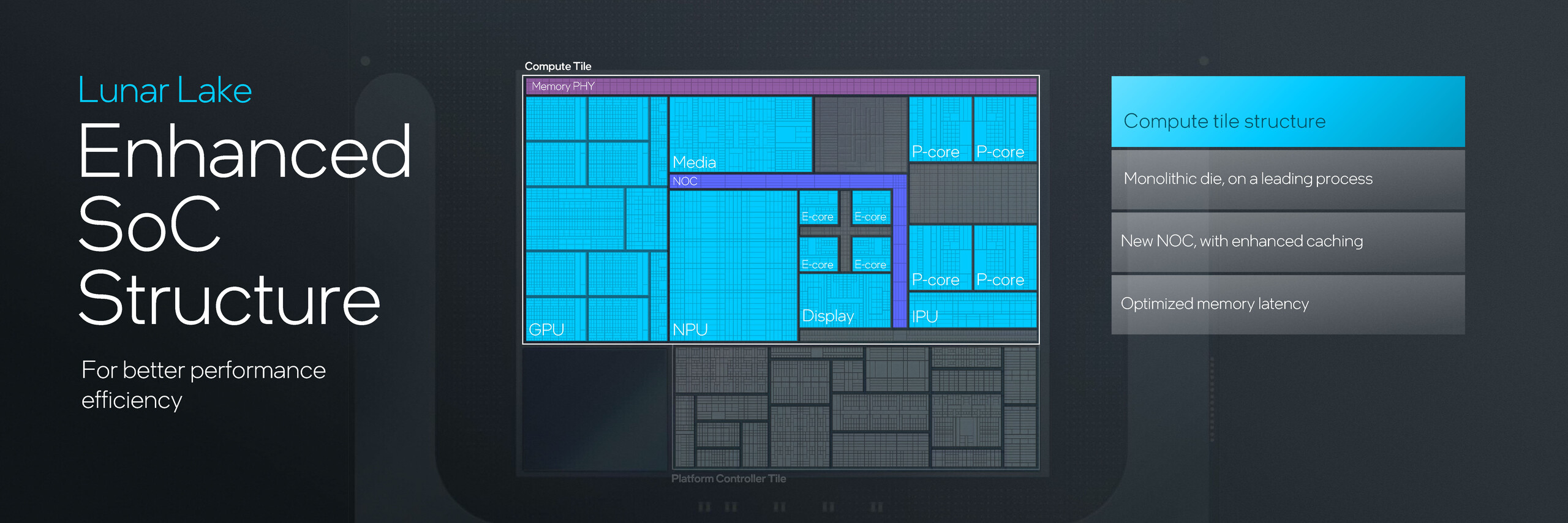
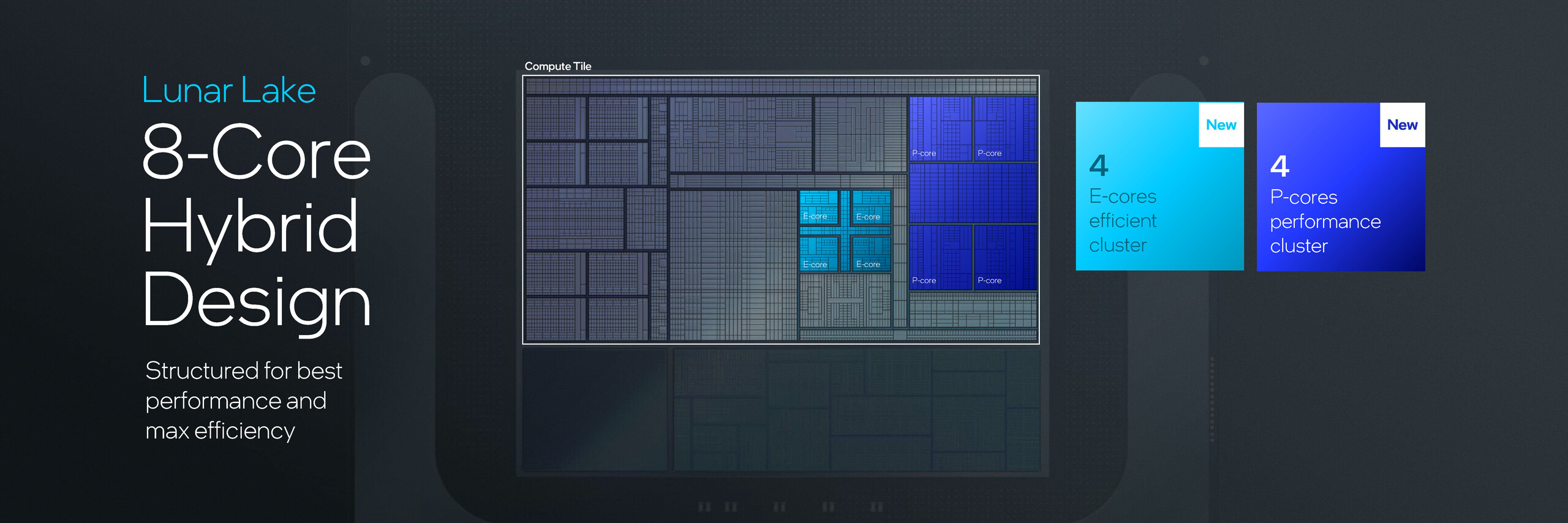
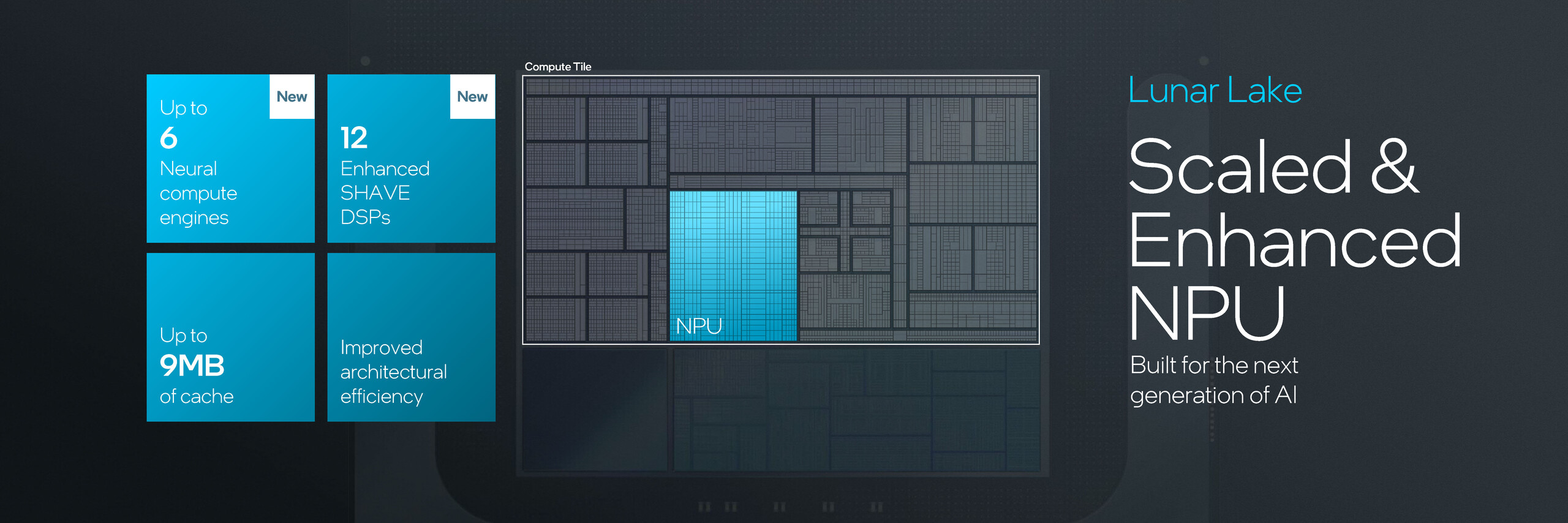
Compute tile składa się z klastrów CPU, Battlemage Xe2-LPG iGPU oraz 48 TOPS NPU. Lunar Lake wykorzystuje hybrydowy układ rdzeni 4P+4E, który według Intela został zoptymalizowany pod kątem lepszej wydajności jednowątkowej.
Każdy z czterech rdzeni Lion Cove P otrzymuje 2,5 MB pamięci podręcznej L2 wraz z 12 MB współdzielonej pamięci podręcznej L3. Rdzenie P nie posiadają hiperwątkowości, a Intel jest przekonany, że dostępne osiem wątków może konkurować z ofertą 8C/16T od AMD. Brak hiperwątkowości prawdopodobnie dotyczy tylko jednostek SKU Lunar Lake, a nie samych rdzeni Lion Cove.
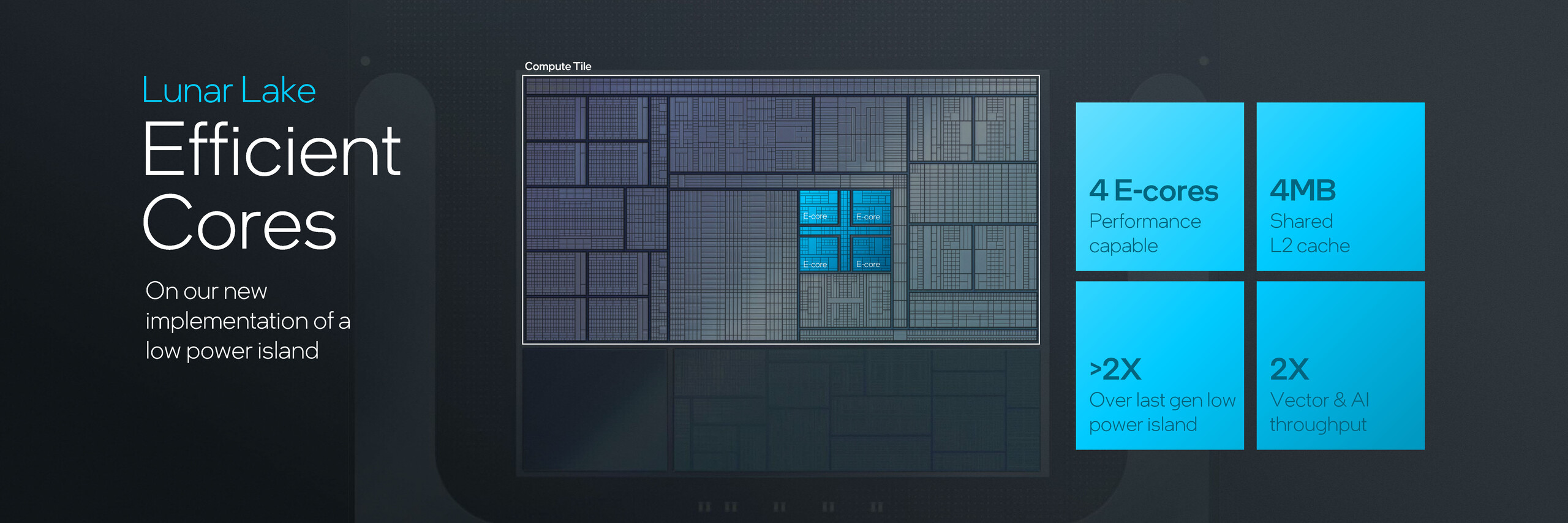
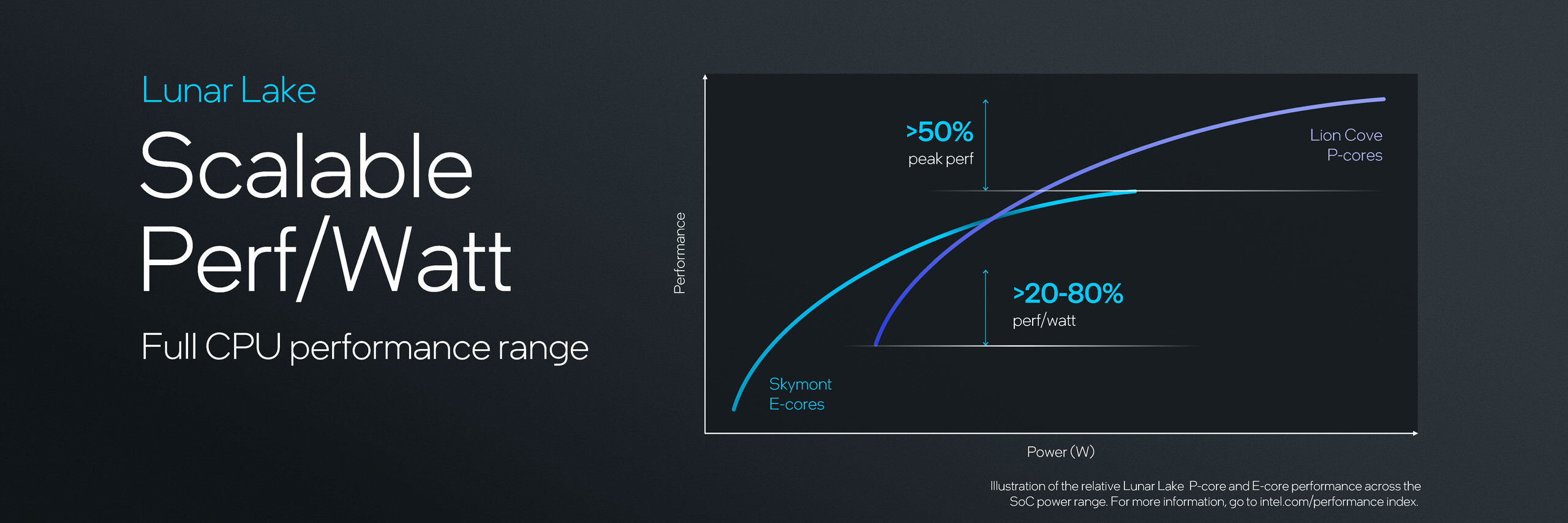
Z drugiej strony, cztery rdzenie Skymont E otrzymują 4 MB współdzielonej pamięci podręcznej L2. Rdzenie Skymont są tym razem szczególnie interesujące, biorąc pod uwagę, że dotychczasowe przecieki wydają się sugerować IPC równoważne z AMD Zen 3. Poniższy wykres Intela wskazuje, że rdzenie Skymont E osiągają do 80% wydajności rdzenia P przy pełnej mocy.
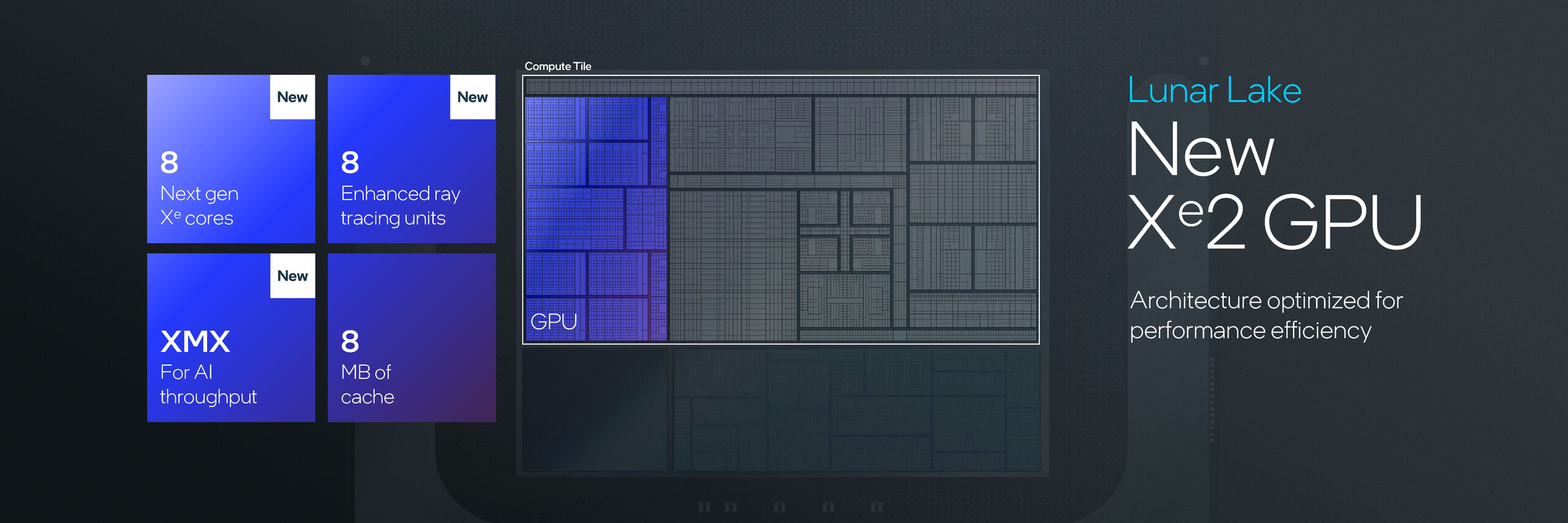
Procesor graficzny Battlemage Arc Intela zadebiutuje na Lunar Lake w postaci Xe2-LPG na długo przed pojawieniem się wersji dyskretnej. Xe2-LPG oferuje osiem rdzeni Xe, osiem rdzeni RT, silnik AI XMX (Xe Matrix eXtensions) i 8 MB pamięci podręcznej.
XMX to odpowiednik rdzeni Nvidia Tensor w kartach GeForce RTX, które są już dostępne w desktopowych kartach Alchemist Arc. Xe2-LPG po raz pierwszy wprowadza XMX do iGPU Arc, co powinno umożliwić wykorzystanie technologii superpróbkowania Intel XeSS przy wyższych ustawieniach jakości.
Według Intela, iGPU Xe2-LPG na referencyjnej platformie walidacyjnej Lunar Lake (RVP) jest do 50% szybsze niż Xe-LPG w Meteor Lake w 3DMark Time Spy. Nie podano jednak dokładnej konfiguracji ani specyfikacji RVP.
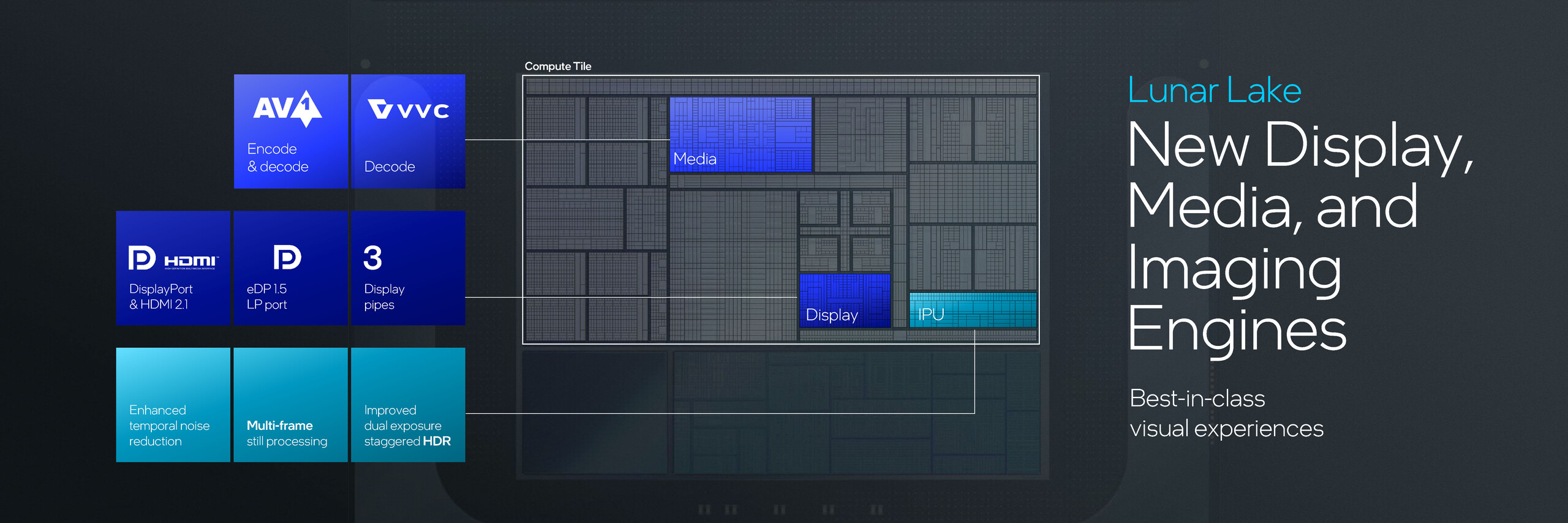
XMX pomaga również w dodaniu kolejnych 67 TOPS do całkowitej wydajności AI. Łącznie, CPU, GPU Xe2-LPG i NPU mogą zapewnić łącznie 120 TOPS wydajności obliczeniowej platformy AI. Lunar Lake wprowadza również nowy silnik multimedialny, który obsługuje kodowanie/dekodowanie AV1 i dekodowanie VVC/H.266.



Zarządzanie energią
Lunar Lake ma również kilka sztuczek w rękawie, aby poprawić wydajność energetyczną. Po pierwsze, po stronie pamięci znajduje się pamięć podręczna zapewniająca niskie zużycie energii. Następnie jest bardziej wydajna wyspa niskiego poboru mocy (LPI), która, miejmy nadzieję, robi nieco więcej niż tylko utrzymywanie urządzenia w stanie niskiego poboru mocy.
Intel dodaje więcej szyn zasilania i świadomą telemetrię, aby umożliwić SoC podejmowanie lepszych decyzji dotyczących zasilania. Wprowadzono również zmiany w Thread Director, aby poprawić wydajność klasyfikacji obciążeń przy użyciu uczenia maszynowego.
Ogólnie rzecz biorąc, Intel twierdzi, że zapotrzebowanie na energię Lunar Lake RVP jest o 40% niższe w porównaniu do Meteor Lake. Dzieje się tak podczas odtwarzania wideo YouTube 4K 30 AV1.
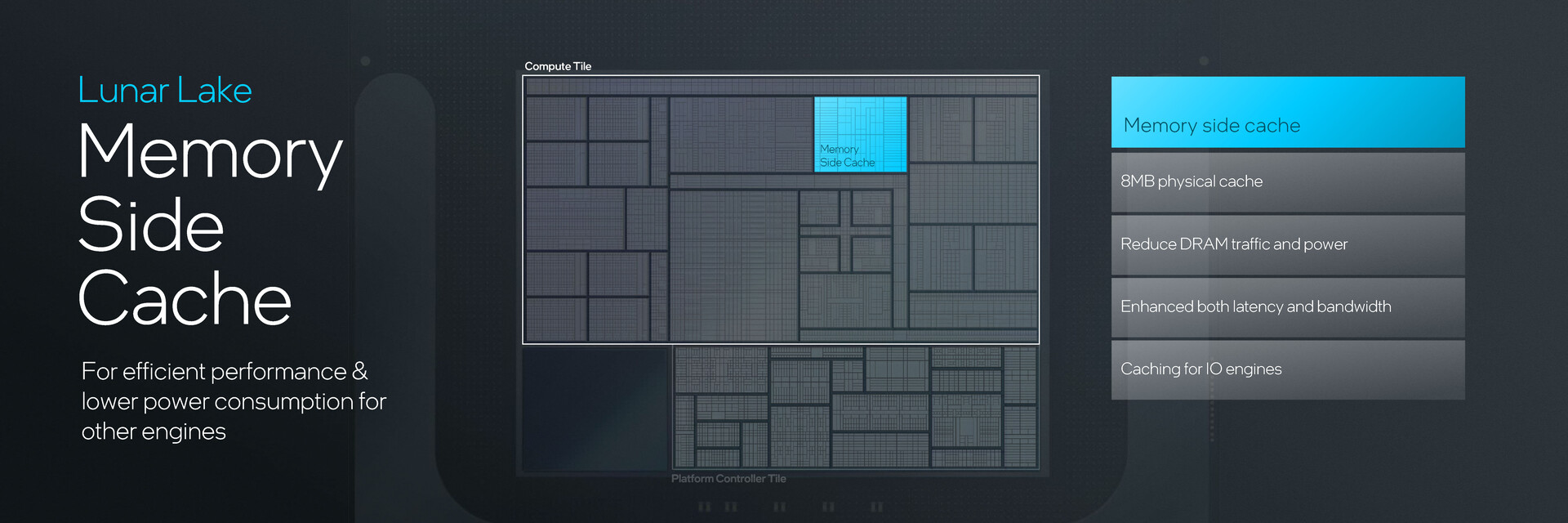


Kafelek kontrolera platformy
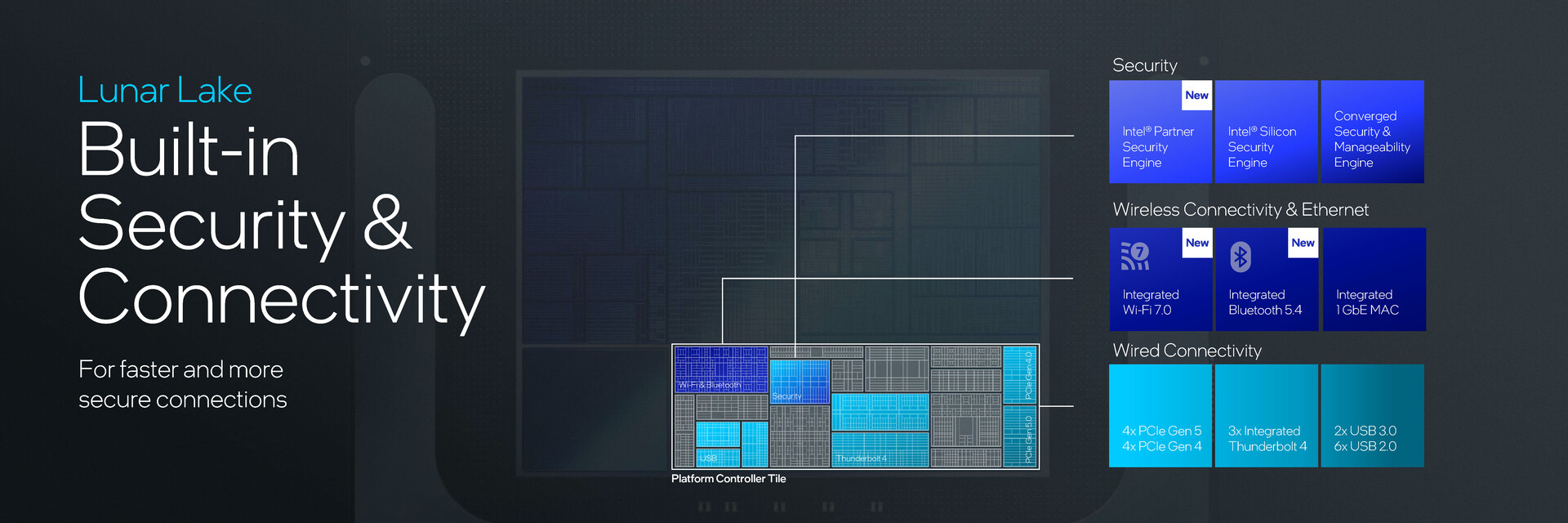
Kafelek kontrolera platformy oferuje wszystkie funkcje sieciowe i wejścia/wyjścia. Lunar Lake integruje teraz Wi-Fi 7 i Bluetooth 5.4, oferując jednocześnie 4x PCIe Gen 5 i PCIe Gen 4 oraz 3x Thunderbolt 4.
Oprócz Silicon Security Engine (SSE), Graphics Security Controller (GSC) i Converged Security and Manageability Engine (CSME), które były już częścią Meteor Lake, pojawił się także nowy Partner Security Engine (PSE).
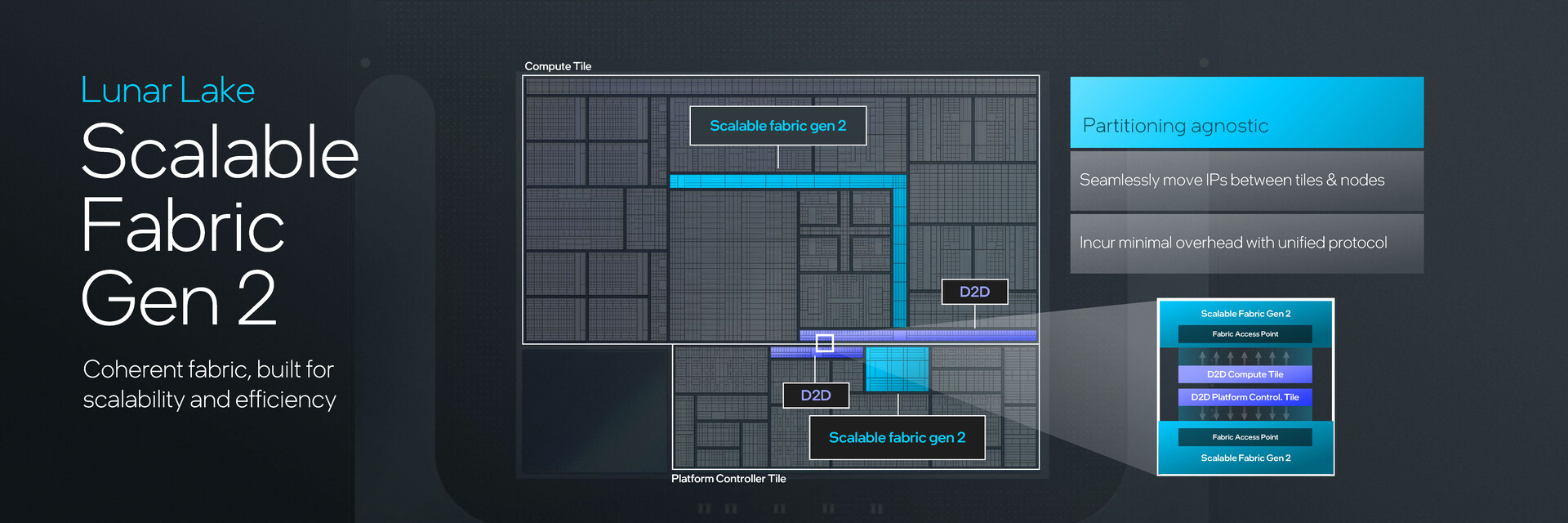
Intel powiedział również, że struktura platformy jest zbudowana z myślą o skalowalności z możliwością przenoszenia IP między kafelkami i węzłami w razie potrzeby.

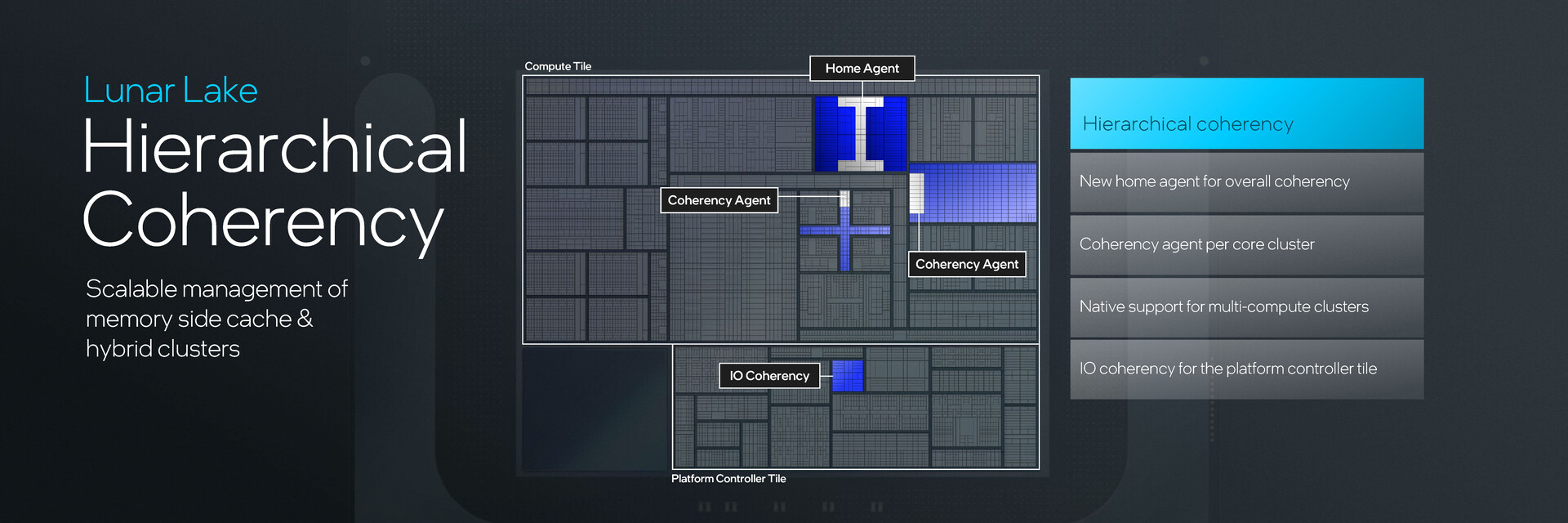
Intel przedstawia Lunar Lake jako mistrza wydajności, a niekoniecznie jako potęgę wydajności. Jest to zrozumiałe, biorąc pod uwagę, że ARM kradnie uwagę od x86 i sposób, w jaki okazuje się być realną platformą do uruchamiania pełnego systemu Windows.
Laptopy z procesorami Lunar Lake zadebiutują na rynku w czwartym kwartale, przed którym powinniśmy uzyskać lepsze wyobrażenie o oferowanych jednostkach SKU.
Jedno jest jednak pewne - x86 w laptopach nie można jeszcze spisać na straty.
Źródło(a)
Motyw przewodni Intel Computex 2024










