

Intel ujawnia architekturę GPU Xe2 "Battlemage", która początkowo zostanie wprowadzona wraz z procesorami Lunar Lake w wersji o niskim poborze mocy

Intel ujawnił więcej szczegółów na temat swojej nadchodzącej architektury GPU Xe2 o nazwie kodowej "Battlemage" podczas Intel Tech Tour poprzedzającego konferencję Computex. Podczas gdy wcześniejsze plotki dotyczące możliwych opóźnień lub nawet całkowitego anulowania architektury GPU następnej generacji Intela wydają się teraz bezpodstawne, wygląda na to, że Battlemage nie zostanie uruchomiony w formie GPU i iGPU w tym samym czasie. Intel planuje najpierw wprowadzić wersję o niskim poborze mocy z układami Lunar Lake a następnie wydać wersje dla komputerów stacjonarnych i HPC w późniejszym czasie. W związku z tym Intel pokazał jedynie szacunkowy wzrost wydajności iGPU w układach Lunar Lake.
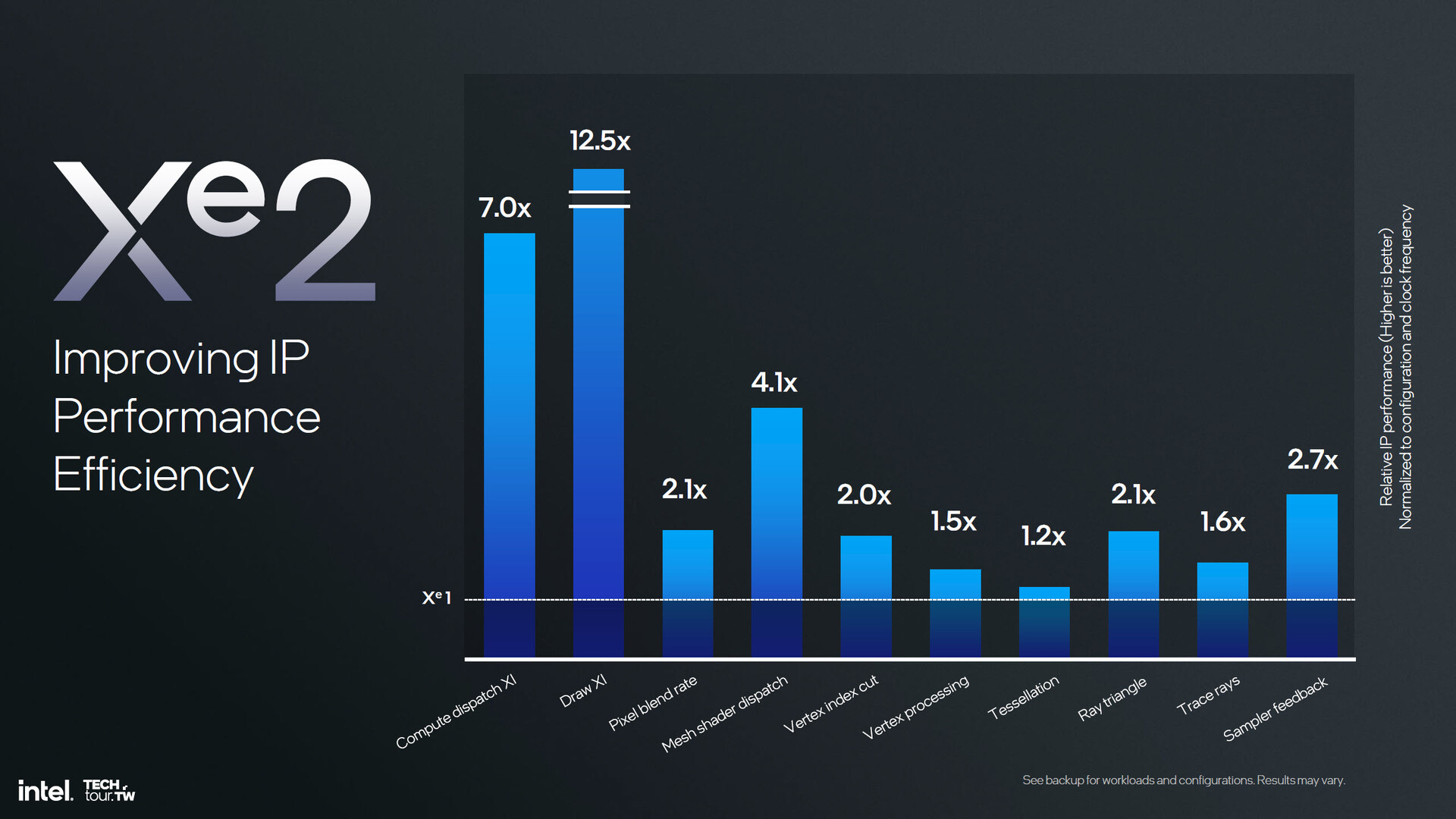
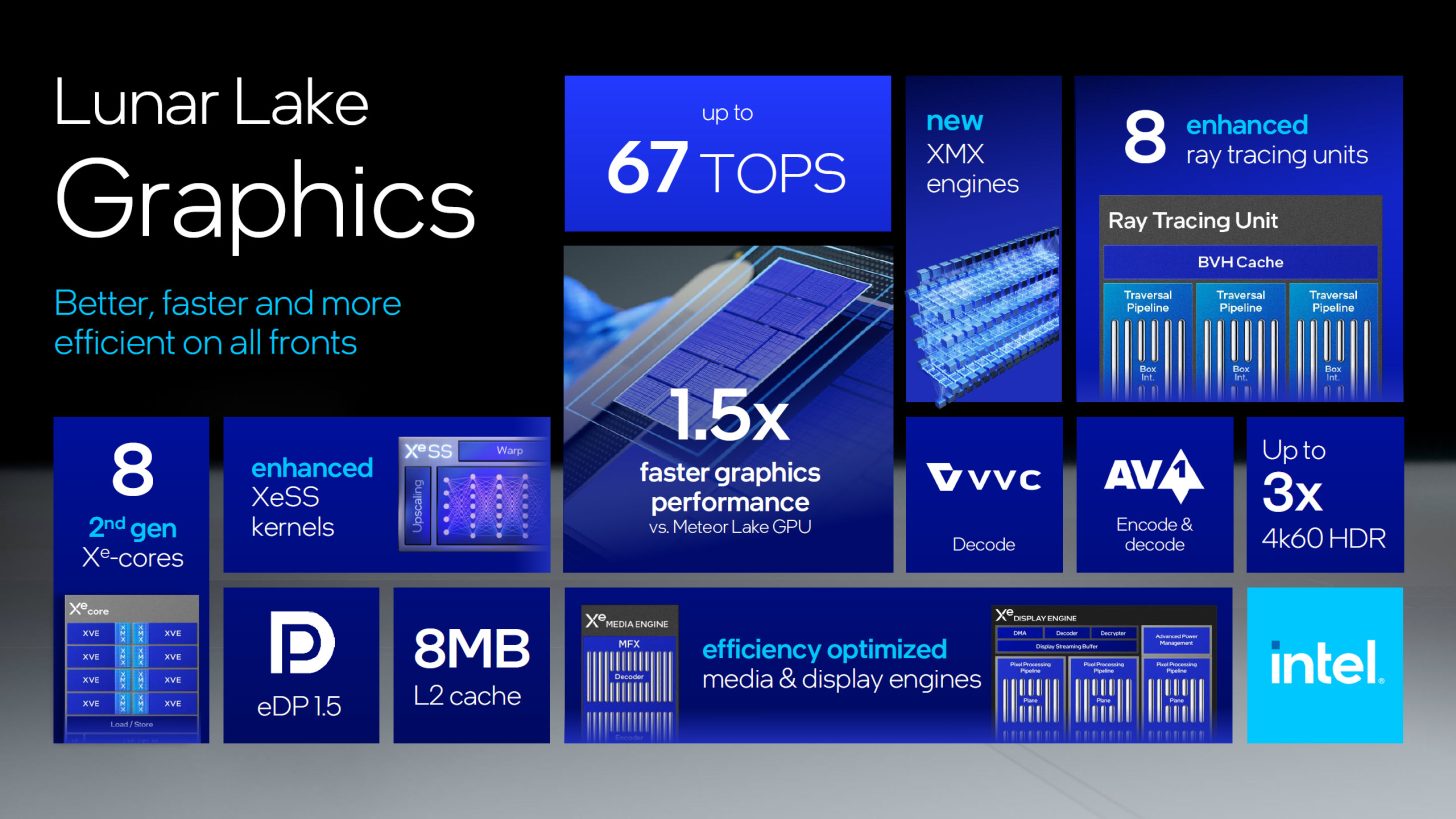
Dzięki architekturze GPU Xe2 Battlemage, Intel koncentruje się na zapewnieniu wyższego wykorzystania, lepszej dystrybucji pracy i zmniejszeniu narzutu sterownika oprogramowania. Jeśli chodzi o wzrost wydajności w stosunku do Xe Alchemistintel obiecuje 12,5-krotnie ulepszone wywołania rysowania, 7-krotnie lepszą wysyłkę obliczeń, 4,1-krotnie lepszą wysyłkę shaderów siatki, by wspomnieć tylko o największych zyskach. Mimo to, aspekty, które mają większy wpływ na ogólną wydajność, takie jak przetwarzanie wierzchołków, teselacja, trójkąty promieni i śledzenie promieni, zostały poprawione co najwyżej 2-krotnie.
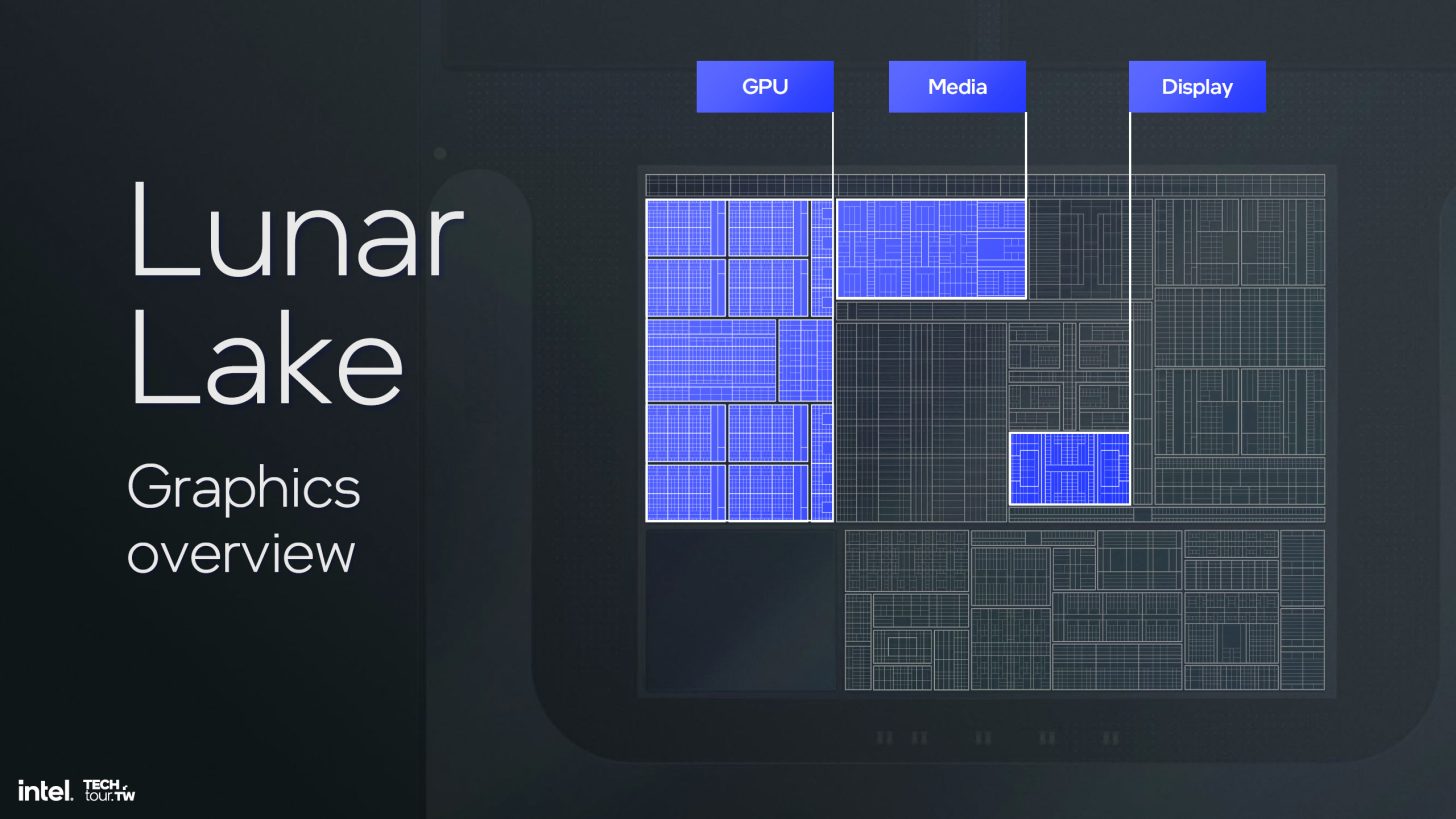
Każdy rdzeń Xe2 posiada 8 x 512-bitowe silniki wektorowe, 8 x 2048-bitowe silniki XMX, obsługę 64b operacji atomowych i 192 KB współdzielonej pamięci podręcznej L1 / SLM. Podobnie jak Xe Alchemist, Xe2 Battlemage jest wysoce skalowalny i będzie posiadał określoną liczbę rdzeni w zależności od stosu produktu. Na przykład iGPU Lunar Lake będą wyposażone w maksymalnie 8 rdzeni Xe2 z 64 silnikami wektorowymi, 2 potokami geometrii, 8 samplerami, 4 backendami pikseli, 8 jednostkami śledzenia promieni i 8 MB pamięci podręcznej L2.
Intel zaktualizował wszystkie silniki wektorowe o natywne jednostki ALU SIMD16, które obsługują również operacje SIMD32, podczas gdy rozszerzenia macierzy Xe obsługują operacje INT2, INT4, INT8. Operacje FP16 i BF16. Prędkości przetwarzania dla operacji FP16 zostały zwiększone do 2048 OPS/taktowanie, a prędkości INT8 mogą osiągnąć 4096 OPS/taktowanie.
Aby zredukować opóźnienia i usprawnić sprzętowo-programowy handshake, Intel wprowadza render slices jako podstawowe bloki dla silnika renderującego. Plastry te są również skalowalne i mogą być układane w stosy i optymalizowane w zależności od typu GPU. Dodatkowo, jednostki Ray Tracing również zostały ulepszone i obejmują 3 potoki Traversal, 18 przecięć pudełek i 2 przecięcia trójkątów.
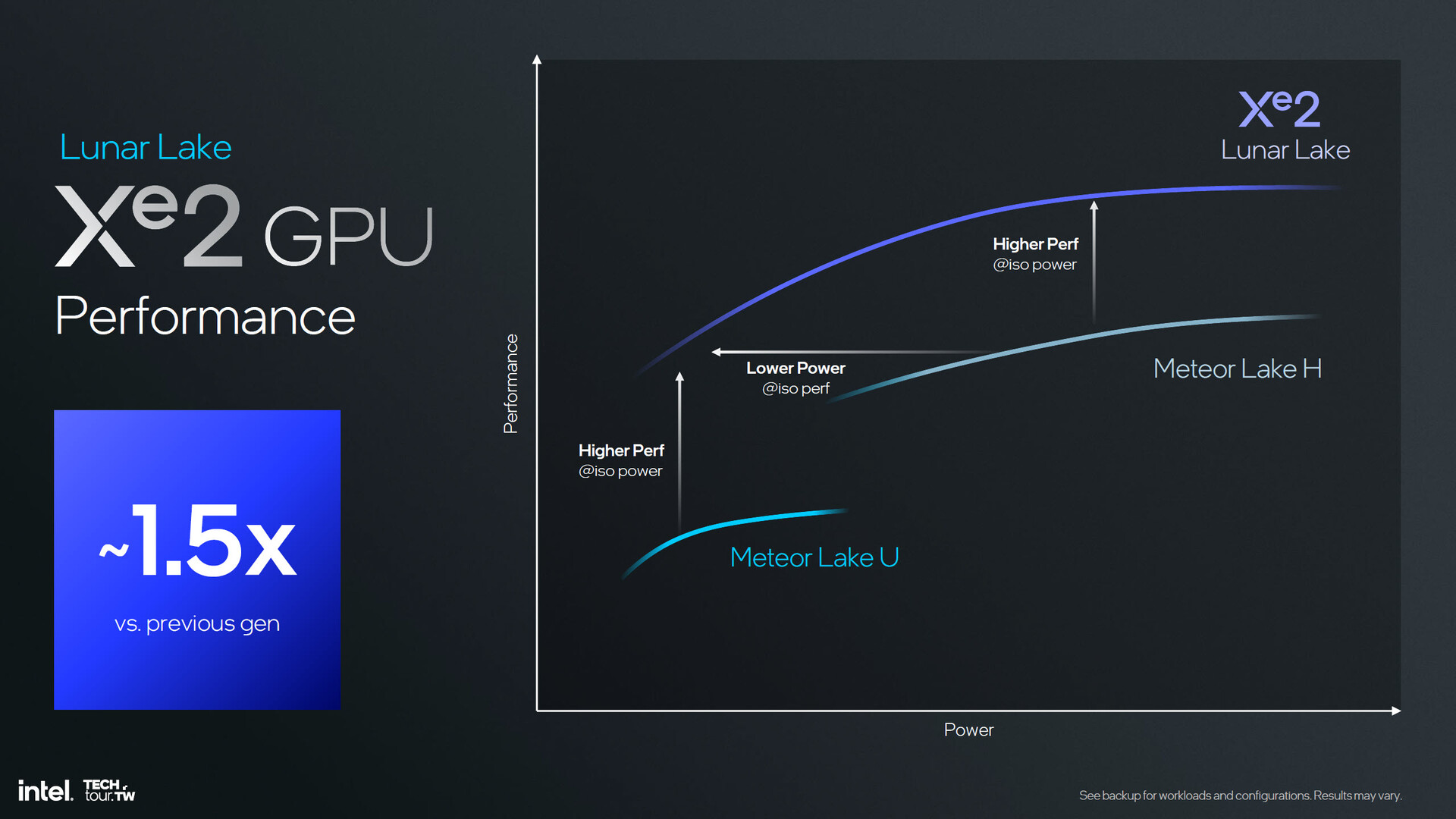
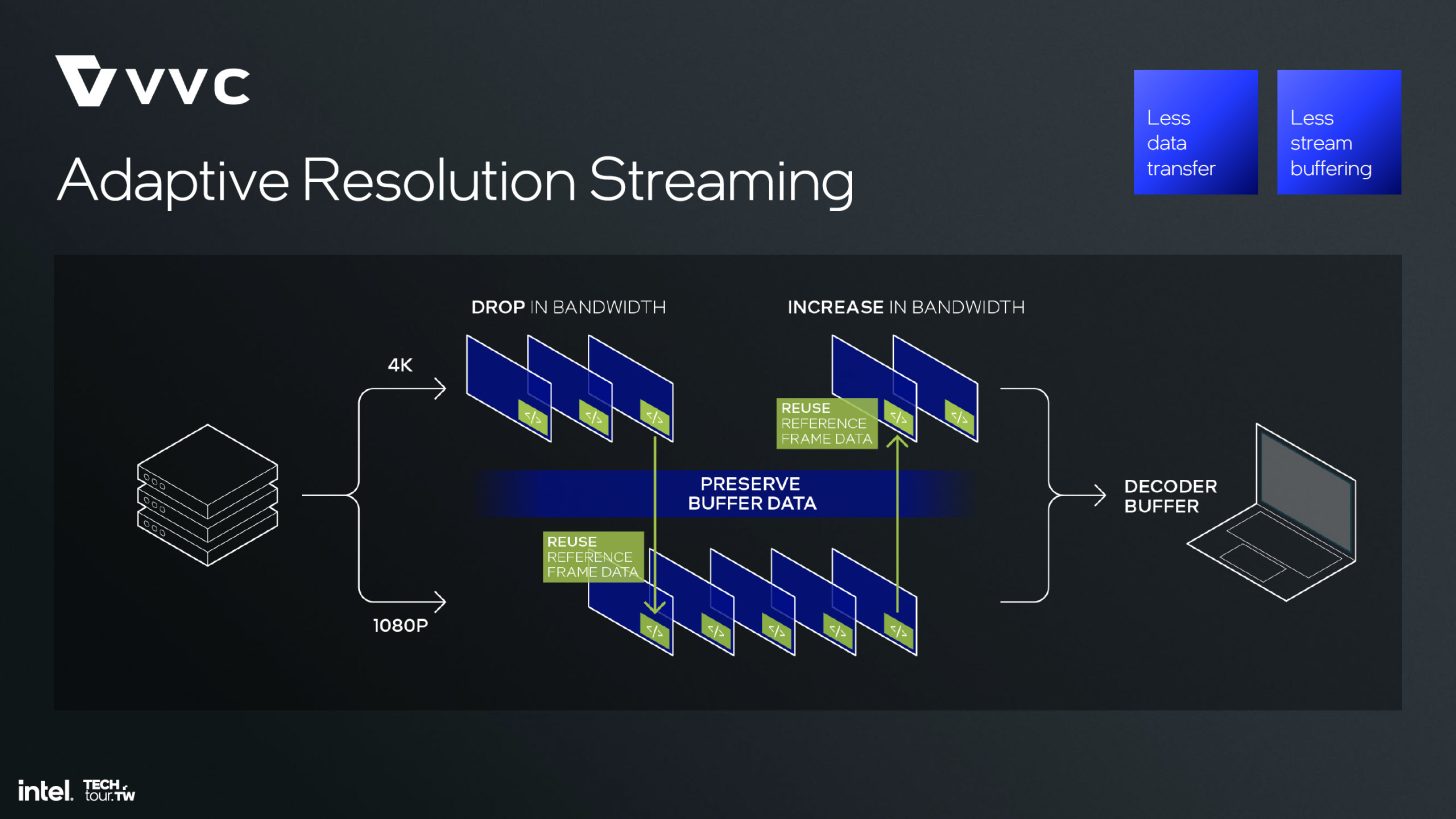
Intel oczekuje, że iGPU Xe2 w procesorach Lunar Lake będą o 50% szybsze niż modele Xe Alchemist w Meteor Lake. Kolejnym ulepszeniem jest nowy silnik Display Engine, który obsługuje eDisplayPort 1.5, co zwiększy wydajność energetyczną i poprawi możliwości adaptacyjnej synchronizacji przy zmniejszonym drganiu na wyświetlaczach laptopów. Co więcej, Intel aktualizuje silnik Media Engine o dedykowaną pamięć podręczną 8 MB, która powinna zwiększyć wydajność energetyczną przy obciążeniach związanych z kodowaniem, a także wprowadza obsługę nowego standardu VVC (Versatile Video Coding), umożliwiając uzyskanie jakości AV1 przy 10% redukcji rozmiaru pliku.


Źródło(a)
przez WCCFTech


![Pierwszy test porównawczy Lunar Lake Xe2 już jest (Źródło obrazu: Intel [edytowane])](fileadmin/_processed_/3/a/csm_Intel-Arc-Xe2-Lunar-Lake-iGPU_c0975cf47d.jpg)









