

Meta prezentuje największą, najmądrzejszą, wolną od opłat licencyjnych sztuczną inteligencję Llama 3.1 405B

Meta zaprezentowała swoją sztuczną inteligencję Llama 3.1 405B do użytku bez tantiem. Duży model językowy (LLM) o pojemności 750 GB i 405 miliardach parametrów jest jednym z największych, jakie kiedykolwiek wydano, co pozwala mu konkurować z rozszerzonym oknem wejściowym 128K tokenów z flagowymi produktami AI, takimi jak Anthropic Claude 3.5 Sonnet i OpenAI GPT-4o. W przeciwieństwie do płatnych, zamkniętych konkurentów, czytelnicy mogą dostosować i uruchomić darmowy LLM na własnych komputerach wyposażonych w niezwykle wydajne karty graficzne Nvidia (GPU).
Tworzenie i energia
Meta wykorzystuje do 16 384 procesorów graficznych 700W TDP Procesorów graficznych H100 na swojej platformie serwerowej Meta Grand Teton AI, aby wyprodukować 3,8 x 10^25 FLOP-ów potrzebnych do stworzenia modelu o 405 miliardach parametrów na 16,55 bilionach tokenów (1000 tokenów to około 750 słów). Awarie związane z procesorami graficznymi spowodowały 57,3% przestojów podczas wstępnego treningu, przy czym 30,1% z nich wynikało z wadliwych procesorów graficznych.
Wstępne szkolenie sztucznej inteligencji na dokumentach trwało ponad 54 dni, a do wytrenowania Llamy 3.1 405B wykorzystano łącznie 39,3 miliona godzin GPU. Szybkie szacunki wskazują, że zużycie energii elektrycznej podczas szkolenia wyniosło ponad 11 GWh, a emisja gazów cieplarnianych odpowiadających emisji CO2 wyniosła 11 390 ton.
Bezpieczeństwo i wydajność
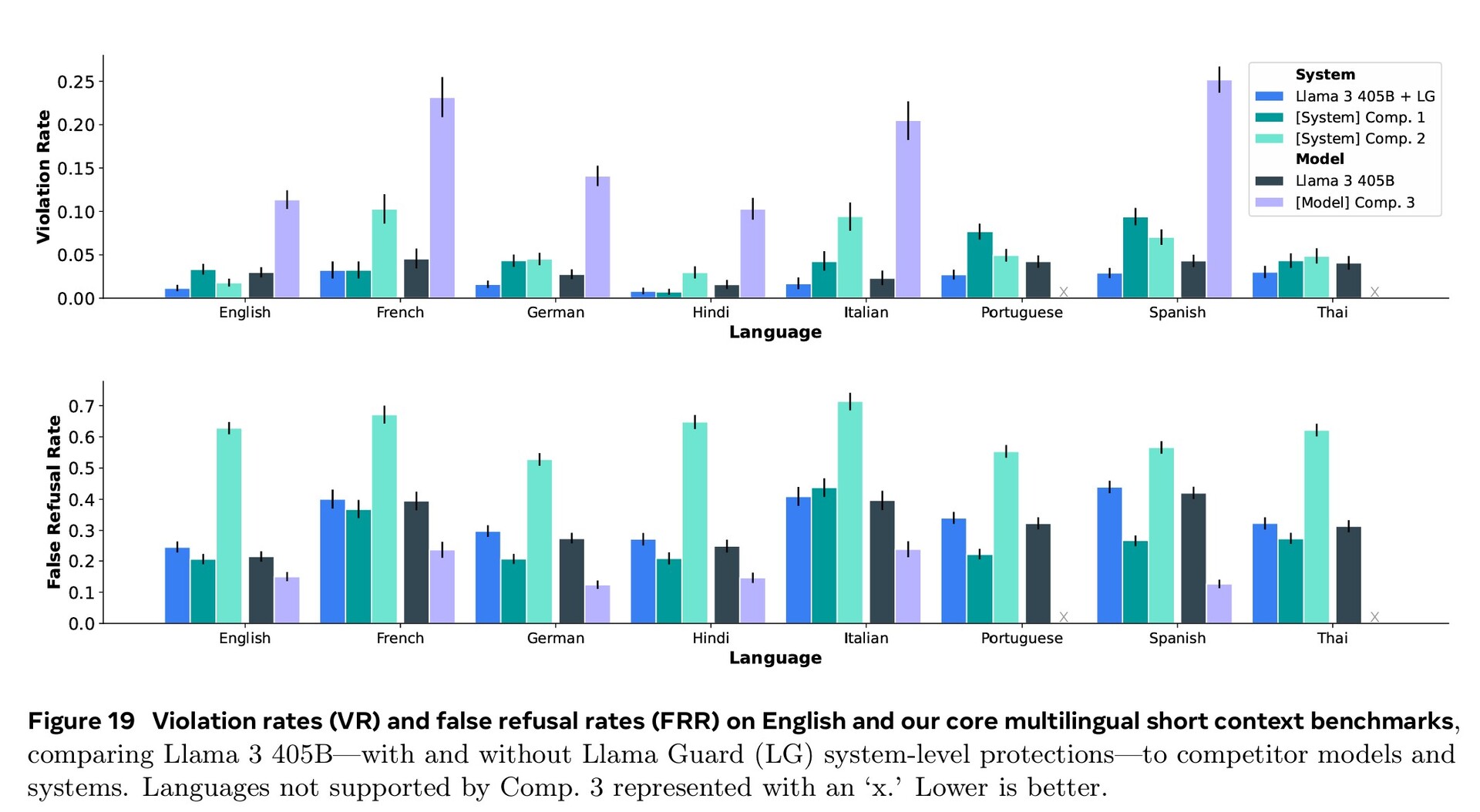
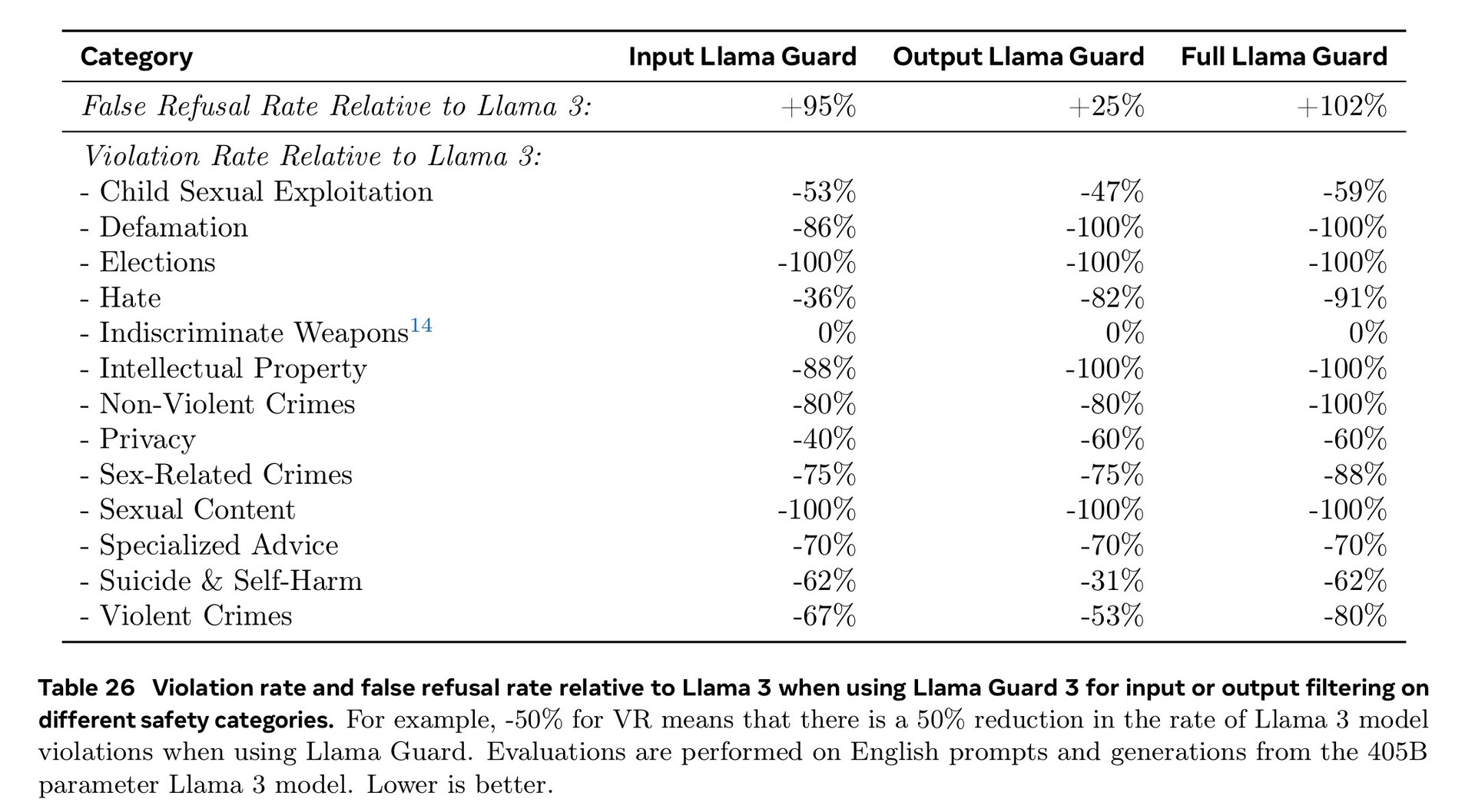
Rozległe szkolenie w zakresie cyberbezpieczeństwa, bezpieczeństwa dzieci, ataków chemicznych i biologicznych, szybkiego wstrzykiwania i innych, wraz z filtrowaniem tekstu wejściowego i wyjściowego za pomocą Llama Guard 3, zaowocowało lepszymi wynikami w zakresie bezpieczeństwa niż konkurencyjne modele sztucznej inteligencji. Mimo to mniejsza liczba dokumentów obcojęzycznych dostępnych do szkolenia oznacza, że Llama 3.1 częściej odpowiada na niebezpieczne pytania w języku portugalskim lub francuskim niż w języku angielskim.
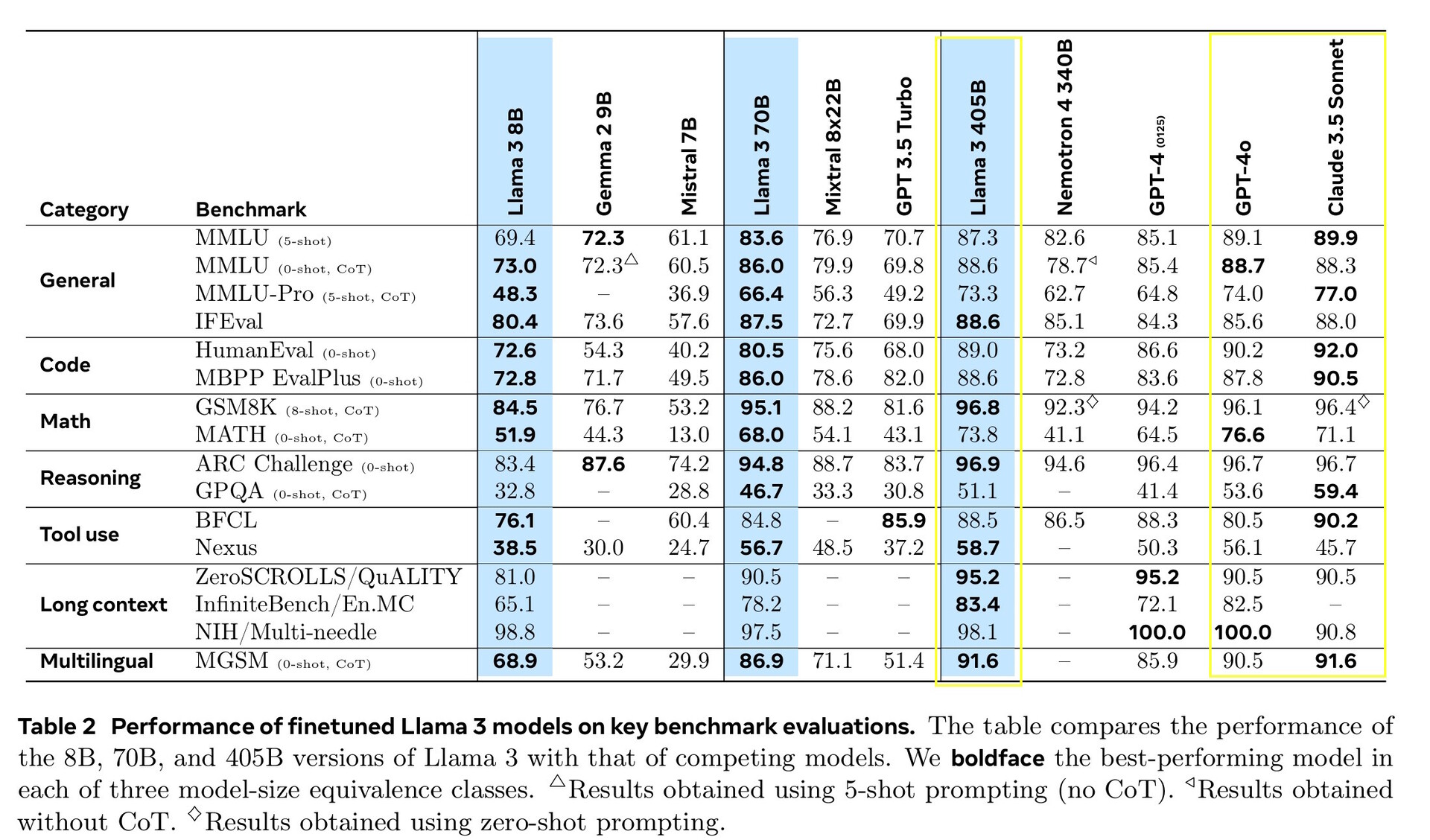
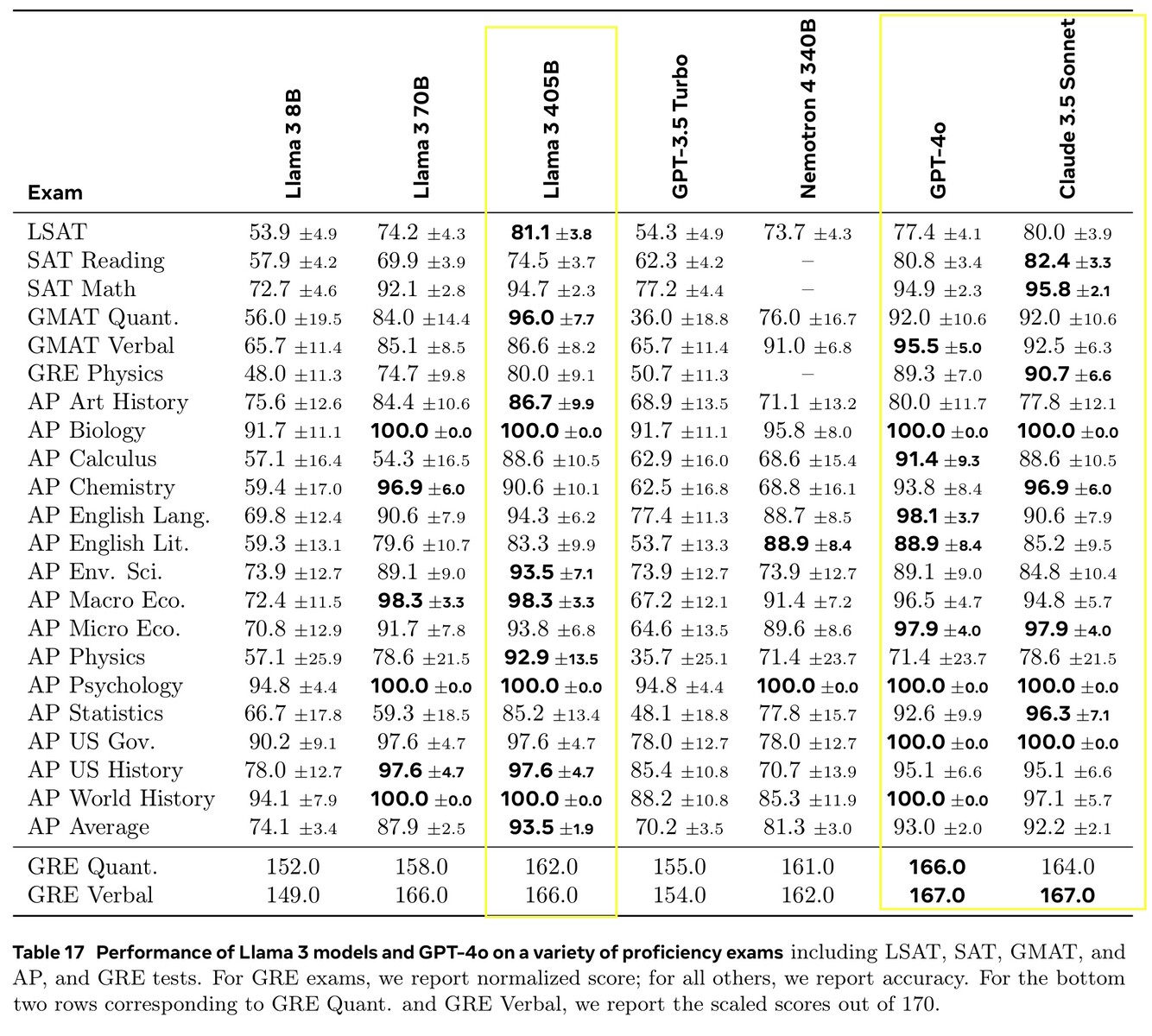
Llama 3.1 405B uzyskała od 51,1 do 96,6% punktów w testach AI na poziomie college'u i absolwenta, zgodnie z wynikami Claude 3.5 Sonnet i GPT-4o. W rzeczywistych testach ocenianych przez ludzi, GPT-4o udzielał lepszych odpowiedzi o 52,9% częściej niż Llama. Model nie wie nic poza datą graniczną wiedzy z grudnia 2023 r., ale może zbierać najnowsze informacje online za pomocą Brave Search, rozwiązywać zadania matematyczne za pomocą Wolfram Alphai rozwiązywać problemy z kodowaniem w interpreterze Pythona https://www.python.org/.
Wymagania
Naukowcy zainteresowani lokalnym uruchomieniem Llama 3.1 405B będą potrzebować bardzo wydajnych komputerów z 750 GB wolnej przestrzeni dyskowej. Uruchomienie pełnego modelu wymaga ośmiu Procesorów graficznych Nvidia A100 lub podobnych, zapewniających dwa węzły MP16 i 810 GB pamięci VRAM GPU do wnioskowania, w systemie z 1 TB pamięci RAM. Meta wydała mniejsze wersje, które wymagają mniej, ale działają gorzej: Llama 3.1 8B i 70B. Llama 3.1 8B potrzebuje tylko 16 GB pamięci GPU VRAM, więc będzie działać dobrze na dobrze wyposażonych Nvidia 4090(jak ten laptop na Amazon) mniej więcej na poziomie GPT-3.5 Turbo. Czytelnicy, którzy po prostu chcą korzystać z topowej sztucznej inteligencji, mogą zainstalować aplikację taką jak Anthropic Android lub aplikacja na iOS.
Źródło(a)
Duży model językowy
Przedstawiamy Państwu Llamę 3.1: Nasze najbardziej wydajne modele do tej pory
23 lipca 2024 r
15 minut czytania
Wnioski:
Meta jest zaangażowana w otwarcie dostępnej sztucznej inteligencji. Proszę przeczytać list Marka Zuckerberga, w którym wyjaśnia on, dlaczego otwarte oprogramowanie jest dobre dla deweloperów, dla firmy Meta i dla całego świata.
Udostępniając otwartą inteligencję wszystkim, nasze najnowsze modele zwiększają długość kontekstu do 128K, dodają obsługę ośmiu języków i obejmują Llama 3.1 405B - pierwszy model open source AI na poziomie granicznym.
Llama 3.1 405B jest klasą samą w sobie, z niezrównaną elastycznością, kontrolą i najnowocześniejszymi możliwościami, które rywalizują z najlepszymi modelami o zamkniętym kodzie źródłowym. Nasz nowy model umożliwi społeczności odblokowanie nowych przepływów pracy, takich jak generowanie danych syntetycznych i destylacja modeli.
Kontynuujemy rozbudowę Llamy, aby stała się systemem, dostarczając więcej komponentów współpracujących z modelem, w tym system referencyjny. Chcemy zapewnić programistom narzędzia do tworzenia własnych niestandardowych agentów i nowych typów zachowań agentowych. Wzmacniamy to nowymi narzędziami bezpieczeństwa i ochrony, w tym Llama Guard 3 i Prompt Guard, aby pomóc w odpowiedzialnym budowaniu. Publikujemy również prośbę o komentarz w sprawie Llama Stack API, standardowego interfejsu, który, mamy nadzieję, ułatwi zewnętrznym projektom wykorzystanie modeli Llama.
Ekosystem jest gotowy do działania dzięki ponad 25 partnerom, w tym AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud i Snowflake, oferującym usługi już pierwszego dnia.
Proszę wypróbować Llama 3.1 405B w USA na WhatsApp i meta.ai, zadając trudne pytanie matematyczne lub kodowe.
ZALECANE LEKTURY
Odpowiedzialne rozszerzanie ekosystemu Llama
Ekosystem lam: Przeszłość, teraźniejszość i przyszłość
Do dziś duże modele językowe typu open source pozostawały w większości w tyle za swoimi zamkniętymi odpowiednikami, jeśli chodzi o możliwości i wydajność. Teraz rozpoczynamy nową erę z otwartym oprogramowaniem na czele. Publicznie udostępniamy Meta Llama 3.1 405B, który naszym zdaniem jest największym i najbardziej wydajnym otwartym modelem fundamentalnym na świecie. Z ponad 300 milionami pobrań wszystkich wersji Llama do tej pory, dopiero się rozkręcamy.
Przedstawiamy Państwu Llama 3.1
Llama 3.1 405B to pierwszy ogólnodostępny model, który rywalizuje z najlepszymi modelami sztucznej inteligencji pod względem najnowocześniejszych możliwości w zakresie wiedzy ogólnej, sterowności, matematyki, korzystania z narzędzi i tłumaczenia wielojęzycznego. Wraz z wydaniem modelu 405B jesteśmy w stanie przyspieszyć innowacje - z bezprecedensowymi możliwościami rozwoju i eksploracji. Wierzymy, że najnowsza generacja Llamy zapoczątkuje nowe aplikacje i paradygmaty modelowania, w tym generowanie danych syntetycznych, aby umożliwić ulepszanie i szkolenie mniejszych modeli, a także destylację modeli - zdolność, która nigdy nie została osiągnięta na taką skalę w open source.
W ramach najnowszej wersji wprowadzamy ulepszone wersje modeli 8B i 70B. Są one wielojęzyczne i mają znacznie dłuższą długość kontekstu wynoszącą 128K, najnowocześniejsze narzędzia i ogólnie większe możliwości wnioskowania. Dzięki temu nasze najnowsze modele mogą obsługiwać zaawansowane przypadki użycia, takie jak streszczanie długich tekstów, wielojęzyczni agenci konwersacyjni i asystenci kodowania. Wprowadziliśmy również zmiany w naszej licencji, umożliwiając programistom korzystanie z wyników modeli Llama - w tym 405B - w celu ulepszania innych modeli. Zgodnie z naszym zobowiązaniem do otwartego oprogramowania, od dziś udostępniamy te modele społeczności do pobrania na llama.meta.com i Hugging Face oraz do natychmiastowego rozwoju na naszym szerokim ekosystemie platform partnerskich.
Ocena modeli
W tym wydaniu oceniliśmy wydajność na ponad 150 zestawach danych porównawczych, które obejmują szeroki zakres języków. Ponadto przeprowadziliśmy szeroko zakrojone oceny na ludziach, które porównują Llama 3.1 z konkurencyjnymi modelami w rzeczywistych scenariuszach. Nasza ocena eksperymentalna sugeruje, że nasz flagowy model jest konkurencyjny z wiodącymi modelami podstawowymi w wielu zadaniach, w tym GPT-4, GPT-4o i Claude 3.5 Sonnet. Dodatkowo, nasze mniejsze modele są konkurencyjne z modelami zamkniętymi i otwartymi, które mają podobną liczbę parametrów.
Architektura modelu
Jako nasz największy jak dotąd model, trenowanie Llama 3.1 405B na ponad 15 bilionach tokenów było dużym wyzwaniem. Aby umożliwić trening w tej skali i osiągnąć wyniki w rozsądnym czasie, znacznie zoptymalizowaliśmy nasz pełny stos treningowy i przenieśliśmy trening naszego modelu na ponad 16 tysięcy procesorów graficznych H100, dzięki czemu model 405B był pierwszym modelem Llama trenowanym w tej skali.
Aby temu zaradzić, dokonaliśmy wyborów projektowych, które koncentrują się na utrzymaniu skalowalności i prostoty procesu tworzenia modeli.
Zdecydowaliśmy się na standardową architekturę modelu transformatora opartego wyłącznie na dekoderze z niewielkimi modyfikacjami, a nie na model mieszanki ekspertów, aby zmaksymalizować stabilność treningu.
Przyjęliśmy iteracyjną procedurę potreningową, w której każda runda wykorzystuje nadzorowane dostrajanie i bezpośrednią optymalizację preferencji. Umożliwiło nam to stworzenie najwyższej jakości danych syntetycznych dla każdej rundy i poprawę wydajności każdej zdolności.
W porównaniu z poprzednimi wersjami Llamy, poprawiliśmy zarówno ilość, jak i jakość danych, których używamy do szkolenia wstępnego i końcowego. Ulepszenia te obejmują opracowanie bardziej starannego przetwarzania wstępnego i potoków kuratorskich dla danych przedtreningowych, opracowanie bardziej rygorystycznego zapewnienia jakości i podejścia do filtrowania danych po treningu.
Zgodnie z oczekiwaniami dotyczącymi skalowania modeli językowych, nasz nowy flagowy model przewyższa mniejsze modele wytrenowane przy użyciu tej samej procedury. Wykorzystaliśmy również model parametrów 405B, aby poprawić jakość post-treningu naszych mniejszych modeli.
Aby wspierać wnioskowanie produkcyjne na dużą skalę dla modelu w skali 405B, skwantyfikowaliśmy nasze modele z 16-bitowej (BF16) do 8-bitowej (FP8) numerycznej, skutecznie obniżając potrzebne wymagania obliczeniowe i umożliwiając uruchomienie modelu w pojedynczym węźle serwera.
Dostrajanie instrukcji i czatów
W Llama 3.1 405B staraliśmy się poprawić pomocność, jakość i szczegółowość instrukcji modelu w odpowiedzi na instrukcje użytkownika, zapewniając jednocześnie wysoki poziom bezpieczeństwa. Naszymi największymi wyzwaniami były obsługa większej liczby funkcji, okno kontekstowe 128K i zwiększone rozmiary modelu.
W post-treningu tworzymy ostateczne modele czatu, wykonując kilka rund dopasowywania do wstępnie wytrenowanego modelu. Każda runda obejmuje nadzorowane dostrajanie (SFT), próbkowanie odrzucenia (RS) i bezpośrednią optymalizację preferencji (DPO). Używamy generowania danych syntetycznych do tworzenia zdecydowanej większości naszych przykładów SFT, iterując wiele razy, aby uzyskać coraz wyższą jakość danych syntetycznych we wszystkich możliwościach. Dodatkowo inwestujemy w wiele technik przetwarzania danych, aby filtrować te syntetyczne dane do najwyższej jakości. Umożliwia nam to skalowanie ilości danych dostrajających we wszystkich możliwościach.
Starannie równoważymy dane, aby stworzyć model o wysokiej jakości we wszystkich funkcjach. Na przykład, utrzymujemy jakość naszego modelu w testach porównawczych z krótkim kontekstem, nawet po rozszerzeniu do kontekstu 128K. Podobnie, nasz model nadal zapewnia maksymalnie pomocne odpowiedzi, nawet gdy dodajemy środki bezpieczeństwa.
System Llama
Modele Llama zawsze miały działać jako część ogólnego systemu, który może orkiestrować kilka komponentów, w tym wywoływać zewnętrzne narzędzia. Naszą wizją jest wyjście poza podstawowe modele, aby zapewnić programistom dostęp do szerszego systemu, który daje im elastyczność w projektowaniu i tworzeniu niestandardowych ofert zgodnych z ich wizją. Myślenie to rozpoczęło się w zeszłym roku, kiedy po raz pierwszy wprowadziliśmy włączenie komponentów spoza podstawowego LLM.
W ramach naszych ciągłych wysiłków na rzecz odpowiedzialnego rozwoju sztucznej inteligencji poza warstwą modelu i pomagania innym w robieniu tego samego, udostępniamy pełny system referencyjny, który zawiera kilka przykładowych aplikacji i obejmuje nowe komponenty, takie jak Llama Guard 3, wielojęzyczny model bezpieczeństwa i Prompt Guard, filtr wstrzykiwania monitów. Te przykładowe aplikacje są open source i mogą być rozwijane przez społeczność.
Wdrożenie komponentów w tej wizji systemu Llama jest nadal fragmentaryczne. Dlatego rozpoczęliśmy współpracę z przemysłem, startupami i szerszą społecznością, aby pomóc lepiej zdefiniować interfejsy tych komponentów. Aby to wesprzeć, publikujemy prośbę o komentarz na GitHub dla tego, co nazywamy "Llama Stack" Llama Stack to zestaw znormalizowanych i opiniowanych interfejsów do tworzenia kanonicznych komponentów toolchain (dostrajanie, generowanie danych syntetycznych) i aplikacji agentowych. Mamy nadzieję, że zostaną one przyjęte w całym ekosystemie, co powinno pomóc w łatwiejszej interoperacyjności.
Czekamy na opinie i sposoby ulepszenia propozycji. Cieszymy się, że możemy rozwijać ekosystem wokół Llamy i obniżać bariery dla programistów i dostawców platform.
Otwartość napędza innowacje
W przeciwieństwie do modeli zamkniętych, wagi modeli Llama są dostępne do pobrania. Deweloperzy mogą w pełni dostosować modele do swoich potrzeb i aplikacji, trenować na nowych zestawach danych i przeprowadzać dodatkowe dostrajanie. Umożliwia to szerszej społeczności programistów i światu pełniejsze wykorzystanie mocy generatywnej sztucznej inteligencji. Deweloperzy mogą w pełni dostosowywać swoje aplikacje i uruchamiać je w dowolnym środowisku, w tym na miejscu, w chmurze, a nawet lokalnie na laptopie - a wszystko to bez udostępniania danych Meta.
Chociaż wielu może twierdzić, że modele zamknięte są bardziej opłacalne, modele Llama oferują jedne z najniższych kosztów na token w branży, zgodnie z testami przeprowadzonymi przez Artificial Analysis. Jak zauważył Mark Zuckerberg, open source zapewni, że więcej ludzi na całym świecie będzie miało dostęp do korzyści i możliwości związanych ze sztuczną inteligencją, że władza nie będzie skoncentrowana w rękach nielicznych, a technologia będzie mogła być wdrażana bardziej równomiernie i bezpiecznie w całym społeczeństwie. Dlatego nadal podejmujemy kroki na drodze do tego, aby sztuczna inteligencja o otwartym dostępie stała się standardem branżowym.
Widzieliśmy, jak społeczność tworzyła niesamowite rzeczy za pomocą poprzednich modeli Llama, w tym kumpla do badań AI zbudowanego z Llama i wdrożonego w WhatsApp i Messengerze, LLM dostosowany do dziedziny medycyny, zaprojektowany, aby pomóc w podejmowaniu decyzji klinicznych, oraz startup non-profit zajmujący się opieką zdrowotną w Brazylii, który ułatwia systemowi opieki zdrowotnej organizowanie i przekazywanie informacji o pacjentach dotyczących ich hospitalizacji, a wszystko to w sposób bezpieczny dla danych. Nie możemy się doczekać, aby zobaczyć, co zbudują z naszymi najnowszymi modelami dzięki sile open source.
Budowanie z Llama 3.1 405B
Dla przeciętnego dewelopera korzystanie z modelu w skali 405B jest wyzwaniem. Chociaż jest to niezwykle potężny model, zdajemy sobie sprawę, że wymaga on znacznych zasobów obliczeniowych i wiedzy specjalistycznej do pracy. Rozmawialiśmy ze społecznością i zdajemy sobie sprawę, że rozwój generatywnej sztucznej inteligencji to o wiele więcej niż tylko podpowiadanie modeli. Chcemy umożliwić wszystkim jak najlepsze wykorzystanie 405B, w tym:
Wnioskowanie w czasie rzeczywistym i wsadowe
Nadzorowane dostrajanie
Ocenę modelu pod kątem konkretnego zastosowania
Ciągłe szkolenie wstępne
Generowanie rozszerzone o pobieranie (RAG)
Wywoływanie funkcji
Generowanie danych syntetycznych
To właśnie tutaj ekosystem Llama może Państwu pomóc. Już pierwszego dnia deweloperzy mogą skorzystać ze wszystkich zaawansowanych możliwości modelu 405B i natychmiast rozpocząć tworzenie. Deweloperzy mogą również odkrywać zaawansowane przepływy pracy, takie jak łatwe w użyciu generowanie danych syntetycznych, postępować zgodnie z gotowymi wskazówkami dotyczącymi destylacji modelu i włączyć płynne RAG z rozwiązaniami partnerów, w tym AWS, NVIDIA i Databricks. Ponadto Groq zoptymalizował wnioskowanie o niskich opóźnieniach dla wdrożeń w chmurze, a Dell osiągnął podobne optymalizacje dla systemów lokalnych.
Współpracowaliśmy z kluczowymi projektami społecznościowymi, takimi jak vLLM, TensorRT i PyTorch, aby zapewnić wsparcie od pierwszego dnia, aby upewnić się, że społeczność jest gotowa do wdrożenia produkcyjnego.
Mamy nadzieję, że nasze wydanie 405B pobudzi również innowacje w szerszej społeczności, aby ułatwić wnioskowanie i dostrajanie modeli tej skali oraz umożliwić kolejną falę badań nad destylacją modeli.
Proszę wypróbować kolekcję modeli Llama 3.1 już dziś
Nie możemy się doczekać, aby zobaczyć, co społeczność zrobi z tą pracą. Istnieje ogromny potencjał do tworzenia nowych, przydatnych doświadczeń przy użyciu wielojęzyczności i zwiększonej długości kontekstu. Dzięki Llama Stack i nowym narzędziom bezpieczeństwa z niecierpliwością czekamy na dalszą odpowiedzialną współpracę ze społecznością open source. Przed wydaniem modelu pracujemy nad identyfikacją, oceną i ograniczeniem potencjalnego ryzyka za pomocą kilku środków, w tym ćwiczeń wykrywania ryzyka przed wdrożeniem poprzez red teaming i dostrajanie bezpieczeństwa. Przykładowo, przeprowadzamy szeroko zakrojony red teaming z ekspertami zewnętrznymi i wewnętrznymi, aby przetestować modele w warunkach skrajnych i znaleźć nieoczekiwane sposoby ich wykorzystania. (Proszę przeczytać więcej o tym, jak odpowiedzialnie skalujemy naszą kolekcję modeli Llama 3.1 w tym wpisie na blogu)
Chociaż jest to nasz największy jak dotąd model, wierzymy, że wciąż jest wiele nowych obszarów do zbadania w przyszłości, w tym bardziej przyjazne dla urządzeń rozmiary, dodatkowe modalności i większe inwestycje w warstwę platformy agenta. Jak zawsze, z niecierpliwością czekamy na wszystkie niesamowite produkty i doświadczenia, które społeczność zbuduje za pomocą tych modeli.
Praca ta była wspierana przez naszych partnerów ze społeczności AI. Chcielibyśmy podziękować i wyrazić uznanie (w kolejności alfabetycznej): Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel, Kaggle, Microsoft Azure, NVIDIA, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI oraz projektowi vLLM opracowanemu w Sky Computing Lab na UC Berkeley.

