

Mistral OCR dokładnie konwertuje złożone dokumenty na edytowalne pliki za pomocą sztucznej inteligencji

Firma Mistral wprowadziła na rynek nowy produkt o nazwie Mistral OCR, oparty na sztucznej inteligencji interfejs API do optycznego rozpoznawania znaków, zaprojektowany z myślą o konwersji drukowanych dokumentów na pliki cyfrowe.
Istnieją miliony drukowanych dokumentów i nieedytowalnych plików PDF, w tym stare akty urodzenia i książki. Oprogramowanie do optycznego rozpoznawania znaków konwertuje tekst i układ tych materiałów źródłowych na edytowalne pliki cyfrowe. Chociaż oprogramowanie OCR z łatwością konwertuje zwykłe dokumenty tekstowe, często ma problemy ze złożonymi tabelami i wykresami, a także językami obcymi.
Mistral OCR został stworzony specjalnie z myślą o wielojęzycznej, złożonej konwersji dokumentów. Dokładność Mistral w konwersji tekstu w 11 językach waha się od 97,00% do 99,54%, co jest wynikiem lepszym niż w przypadku ofert Microsoft i Google AI OCR. Jego dokładność jest również wyższa niż testowanych konkurentów w przypadku złożonych konwersji dokumentów, takich jak te obejmujące matematykę lub tabele.
Interfejs API Mistral OCR jest obecnie ograniczony do przesyłanych dokumentów o rozmiarze mniejszym niż 50 MB i długości mniejszej niż 1000 stron. Drukowane dokumenty muszą być najpierw zdigitalizowane przez skanery , takie jak ten na Amazon, podczas gdy pliki PDF, obrazy i strony internetowe mogą być przetwarzane bezpośrednio.
Źródło(a)
Mistral OCR
Przedstawiamy najlepszy na świecie interfejs API do rozpoznawania dokumentów.
Badania
6 marca 2025 r
Zespół Mistral AI
W całej historii postęp w abstrakcji i wyszukiwaniu informacji napędzał ludzki postęp. Od hieroglifów po papirusy, od prasy drukarskiej po cyfryzację, każdy skok sprawił, że ludzka wiedza stała się bardziej dostępna i możliwa do wykorzystania, napędzając dalsze innowacje.
Dziś jesteśmy u progu kolejnego wielkiego skoku - odblokowania zbiorowej inteligencji wszystkich zdigitalizowanych informacji. Około 90% danych organizacyjnych na świecie jest przechowywanych w postaci dokumentów i aby wykorzystać ten potencjał, wprowadzamy Mistral OCR.
Mistral OCR to interfejs API optycznego rozpoznawania znaków, który wyznacza nowy standard rozumienia dokumentów. W przeciwieństwie do innych modeli, Mistral OCR rozumie każdy element dokumentów - media, tekst, tabele, równania - z niespotykaną dokładnością i poznaniem. Przyjmuje obrazy i pliki PDF jako dane wejściowe i wyodrębnia zawartość w uporządkowanym, przeplatanym tekście i obrazach.
W rezultacie Mistral OCR jest idealnym modelem do wykorzystania w połączeniu z systemem RAG przyjmującym jako dane wejściowe dokumenty multimodalne (takie jak slajdy lub złożone pliki PDF).
Uczyniliśmy Mistral OCR domyślnym modelem rozumienia dokumentów dla milionów użytkowników Le Chat i udostępniamy API mistral-ocr-latest w cenie 1000 stron za dolara (i około dwukrotnie więcej stron za dolara z wnioskowaniem wsadowym). API jest dostępne już dziś w naszym pakiecie deweloperskim la Plateforme, a wkrótce będzie dostępne dla naszych partnerów w chmurze i inferencji, a także lokalnie.
Najważniejsze cechy
Najnowocześniejsze rozumienie złożonych dokumentów
Natywnie wielojęzyczne i multimodalne
Najwyższy poziom testów porównawczych
Najszybszy w swojej kategorii
Ustrukturyzowane dane wyjściowe w formie dokumentów
Selektywnie dostępny do samodzielnego hostowania dla organizacji zajmujących się wysoce wrażliwymi lub niejawnymi informacjami
Przyjrzyjmy się każdemu z nich.
Najnowocześniejsze rozumienie złożonych dokumentów
Mistral OCR doskonale radzi sobie ze zrozumieniem złożonych elementów dokumentów, w tym przeplatanych obrazów, wyrażeń matematycznych, tabel i zaawansowanych układów, takich jak formatowanie LaTeX. Model umożliwia głębsze zrozumienie bogatych dokumentów, takich jak prace naukowe z wykresami, grafami, równaniami i liczbami.
Poniżej znajduje się przykład modelu wyodrębniającego tekst oraz obrazy z danego pliku PDF do pliku markdown. Dostęp do notatnika można uzyskać tutaj.
Poniżej znajduje się porównanie plików PDF i ich wyników OCR. Proszę najechać kursorem na suwak, aby przełączać się między danymi wejściowymi i wyjściowymi.
Tabele + rysunki
3 Przykład
Wynik OCR
3 Ocr
Matematyka
4 Przykład
Wynik OCR
4 Ocr
Hindi
5 Przykład
Wynik OCR
Hindi Ocr
Dokument
6 Przykład
Wynik OCR
6 Ocr
Arabski
7 Przykład
Wynik OCR
Arabski OCR
Najlepsze testy porównawcze
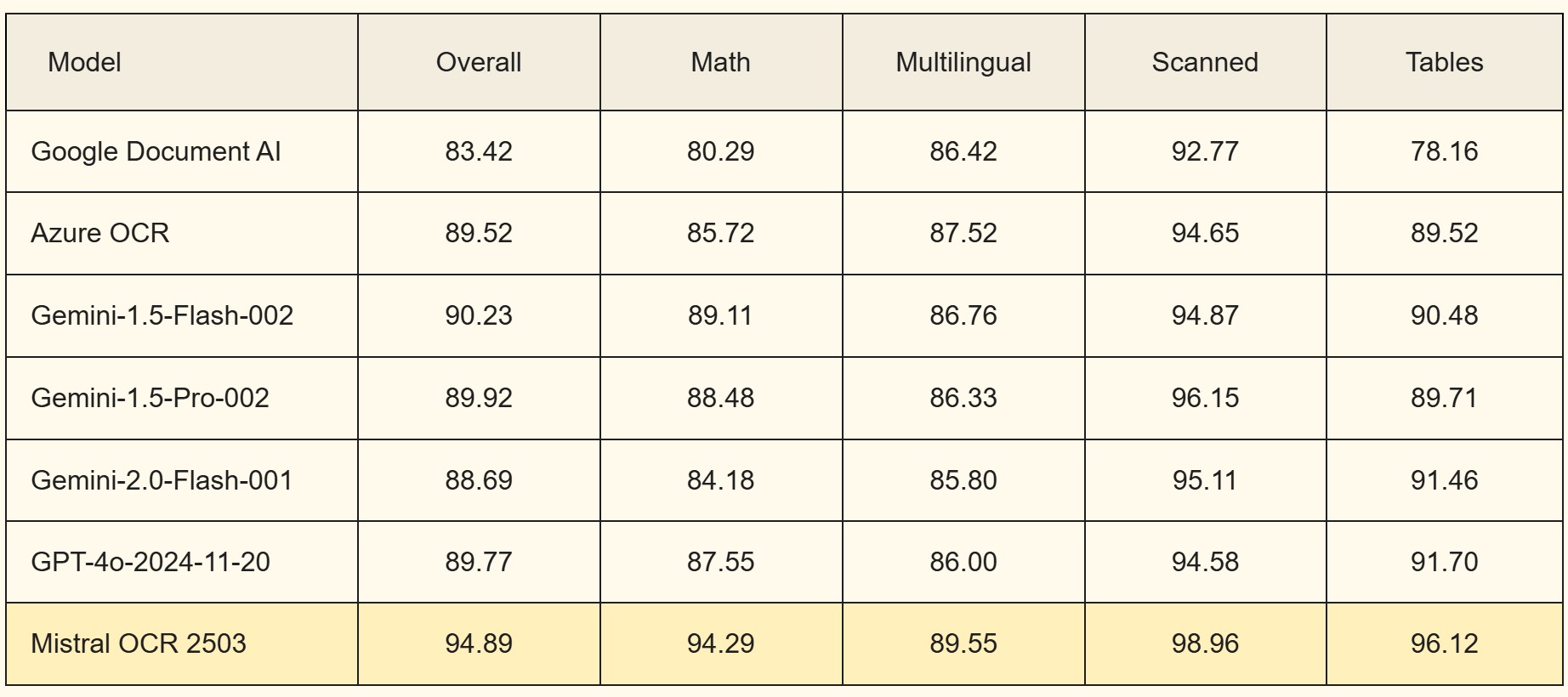
Mistral OCR konsekwentnie przewyższa inne wiodące modele OCR w rygorystycznych testach porównawczych. Jego najwyższą dokładność w wielu aspektach analizy dokumentów zilustrowano poniżej. Wyodrębniamy osadzone obrazy z dokumentów wraz z tekstem. Inne porównywane poniżej modele LLM nie mają takiej możliwości. Aby uzyskać rzetelne porównanie, oceniamy je na naszym wewnętrznym zestawie testowym "tylko tekst" zawierającym różne publikacje i pliki PDF z Internetu; poniżej:
Model Ogólny Matematyczny Wielojęzyczny Zeskanowany Tabele
Google Document AI 83,42 80,29 86,42 92,77 78,16
Azure OCR 89.52 85.72 87.52 94.65 89.52
Gemini-1.5-Flash-002 90.23 89.11 86.76 94.87 90.48
Gemini-1.5-Pro-002 89.92 88.48 86.33 96.15 89.71
Gemini-2.0-Flash-001 88.69 84.18 85.80 95.11 91.46
GPT-4o-2024-11-20 89.77 87.55 86.00 94.58 91.70
Mistral OCR 2503 94.89 94.29 89.55 98.96 96.12
Natywnie wielojęzyczny
Od momentu powstania firmy Mistral aspirowaliśmy do służenia światu naszymi modelami, a co za tym idzie, dążyliśmy do zapewnienia wielojęzycznych możliwości w całej naszej ofercie. Mistral OCR przenosi to na nowy poziom, będąc w stanie analizować, rozumieć i transkrybować tysiące skryptów, czcionek i języków na wszystkich kontynentach. Ta wszechstronność ma kluczowe znaczenie zarówno dla globalnych organizacji, które obsługują dokumenty z różnych środowisk językowych, jak i dla hiperlokalnych firm obsługujących niszowe rynki.
Model Fuzzy Match in Generation
Google-Document-AI 95.88
Gemini-2.0-Flash-001 96.53
Azure OCR 97.31
Mistral OCR 2503 99.02
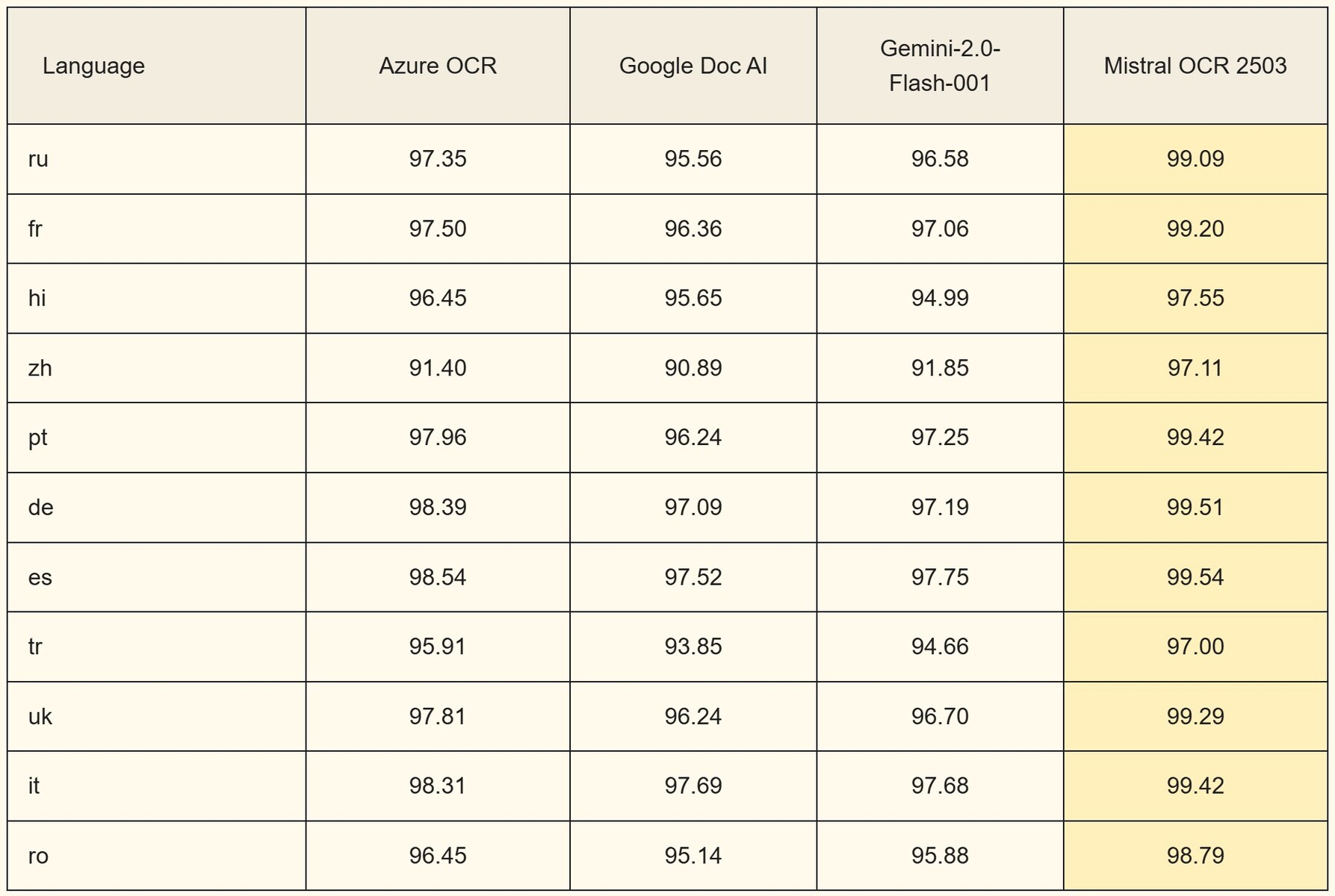
Testy porównawcze według języka:
Język Azure OCR Google Doc AI Gemini-2.0-Flash-001 Mistral OCR 2503
ru 97.35 95.56 96.58 99.09
fr 97.50 96.36 97.06 99.20
hi 96.45 95.65 94.99 97.55
zh 91.40 90.89 91.85 97.11
pt 97.96 96.24 97.25 99.42
de 98.39 97.09 97.19 99.51
es 98.54 97.52 97.75 99.54
tr 95.91 93.85 94.66 97.00
uk 97.81 96.24 96.70 99.29
it 98.31 97.69 97.68 99.42
ro 96.45 95.14 95.88 98.79
Najszybszy w swojej kategorii
Będąc lżejszym niż większość modeli w tej kategorii, Mistral OCR działa znacznie szybciej niż jego odpowiedniki, przetwarzając do 2000 stron na minutę w jednym węźle. Zdolność do szybkiego przetwarzania dokumentów zapewnia ciągłe uczenie się i doskonalenie nawet w środowiskach o wysokiej przepustowości.
Dokument jako monit, ustrukturyzowane dane wyjściowe
Mistral OCR wprowadza również wykorzystanie dokumentów jako podpowiedzi, umożliwiając bardziej wydajne i precyzyjne instrukcje. Ta funkcja pozwala użytkownikom wyodrębniać określone informacje z dokumentów i formatować je w ustrukturyzowanych danych wyjściowych, takich jak JSON. Użytkownicy mogą łączyć wyodrębnione dane wyjściowe w kolejne wywołania funkcji i tworzyć agenty. Proszę zobaczyć ten przykładowy notatnik.
Dostępne do samodzielnego hostowania na zasadzie selektywnej
Dla organizacji o rygorystycznych wymaganiach dotyczących prywatności danych, Mistral OCR oferuje opcję samodzielnego hostingu. Gwarantuje to, że poufne lub niejawne informacje pozostaną bezpieczne w Państwa własnej infrastrukturze, zapewniając zgodność ze standardami regulacyjnymi i bezpieczeństwa. Jeśli chcieliby Państwo zbadać z nami możliwość samodzielnego wdrożenia, prosimy o kontakt.
Przypadki użycia
Umożliwiamy naszym klientom w wersji beta poszerzanie wiedzy organizacyjnej poprzez przekształcanie ich obszernych repozytoriów dokumentów w działania i rozwiązania. Niektóre z kluczowych przypadków użycia, w których nasza technologia ma znaczący wpływ, obejmują
Digitalizacja badań naukowych: Wiodące instytucje badawcze eksperymentują z Mistral OCR w celu konwersji artykułów naukowych i czasopism do formatów gotowych na sztuczną inteligencję, dzięki czemu są one dostępne dla dalszych silników wywiadowczych. Ułatwiło to wymiernie szybszą współpracę i przyspieszyło naukowe przepływy pracy.
Ochrona dziedzictwa historycznego i kulturowego: Organizacje i organizacje non-profit, które są opiekunami dziedzictwa kulturowego, używają Mistral OCR do digitalizacji historycznych dokumentów i artefaktów, zapewniając ich zachowanie i udostępniając je szerszej publiczności.
Usprawnienie obsługi klienta: Działy obsługi klienta wykorzystują Mistral OCR do przekształcania dokumentacji i podręczników w zindeksowaną wiedzę, skracając czas reakcji i zwiększając zadowolenie klientów.
Przygotowanie literatury z zakresu projektowania, edukacji, prawa itp. AI ready: Mistral OCR pomaga również firmom przekształcać literaturę techniczną, rysunki inżynieryjne, notatki z wykładów, prezentacje, dokumenty regulacyjne i wiele innych w zindeksowane, gotowe do odpowiedzi formaty, odblokowując inteligencję i produktywność w milionach dokumentów.
Proszę przekonać się już dziś
Możliwości Mistral OCR można wypróbować bezpłatnie na le Chat. Aby wypróbować API, proszę przejść do la Plateforme. Chętnie poznamy Państwa opinie; spodziewamy się, że w nadchodzących tygodniach model będzie jeszcze lepszy. W ramach naszych strategicznych programów zaangażowania będziemy również oferować wdrożenie lokalne na zasadzie selektywności.

