

Wyciekły wewnętrzne komunikaty ujawniające, że Nvidia codziennie pobiera filmy z YouTube o wartości całego życia, aby trenować model sztucznej inteligencji wideo, a Jensen jest zadowolony z postępów

Nvidia szkoli swoje Omniverse, samojezdne samochody i samochody "cyfrowego człowieka" w oparciu o dane pobrane z "80 lat filmów dziennie" z YouTube i innych źródeł, ujawniło dochodzenie przeprowadzone przez 404 Media.
Wyciekła wewnętrzna komunikacja uzyskana przez 404 Media wskazuje, że Nvidia wykorzystuje te dane do trenowania swojego modelu świata wideo AI o nazwie Cosmos (nie mylić z istniejącą usługą Deep Learning firmy Cosmos)). Cosmos jest wewnętrznie planowany jako model, który zasilałby inne linie Nvidii, w tym GeForce, architekturę GPU, DGX, ramy głębokiego uczenia, Omniverse, Avatar, Project GR00T i pojazdy autonomiczne.
Kierownictwo Nvidii określiło Cosmos jako najnowocześniejszy model fundamentalny, "który obejmuje symulację transportu światła, fizyki i inteligencji w jednym miejscu, aby odblokować różne dalsze aplikacje o krytycznym znaczeniu dla Nvidii"
404 Media uzyskało dostęp do wewnętrznych wiadomości pracowników Slack, które ujawniły, w jaki sposób pracownicy korzystali z wiersza poleceń yt-dlp do pobierania filmów z YouTube przy użyciu od 20 do 30 maszyn wirtualnych AWS, które odświeżają adresy IP, aby uniknąć zablokowania przez YouTube. Witryna do udostępniania filmów była głównym źródłem skrobania filmów, a pracownicy zastanawiali się również nad innymi źródłami, takimi jak Netflix i Discovery Channel.
Komunikacja na Slacku pokazuje, że pracownicy dyskutują o prawnych konsekwencjach skrobania treści chronionych prawem autorskim w celu szkolenia sztucznej inteligencji tylko po to, by zostać odrzuconym przez kierowników projektów jako decyzja wykonawcza, o którą nie muszą się martwić.
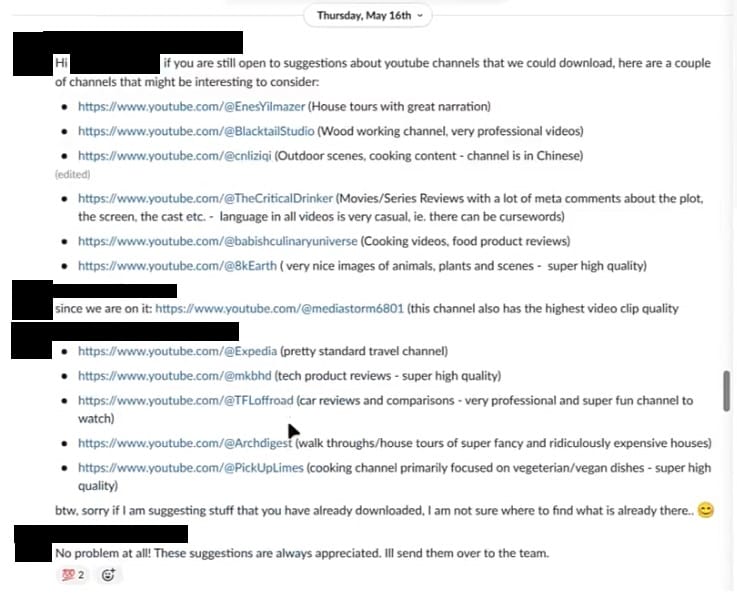
Popularne kanały YouTube, które pracownicy Nvidii znaleźli na krótkiej liście, to między innymi MKBHD, PickUpLimes, Architectural Digest, Expedia, Mediastorm6801, 8kEarth i The CriticalDrinker.
Po skontaktowaniu się z 404 Media, zarówno YouTube, jak i Netflix stwierdziły, że skrobanie treści na ich platformach w celu trenowania modeli sztucznej inteligencji stanowi wyraźne naruszenie ich warunków świadczenia usług.
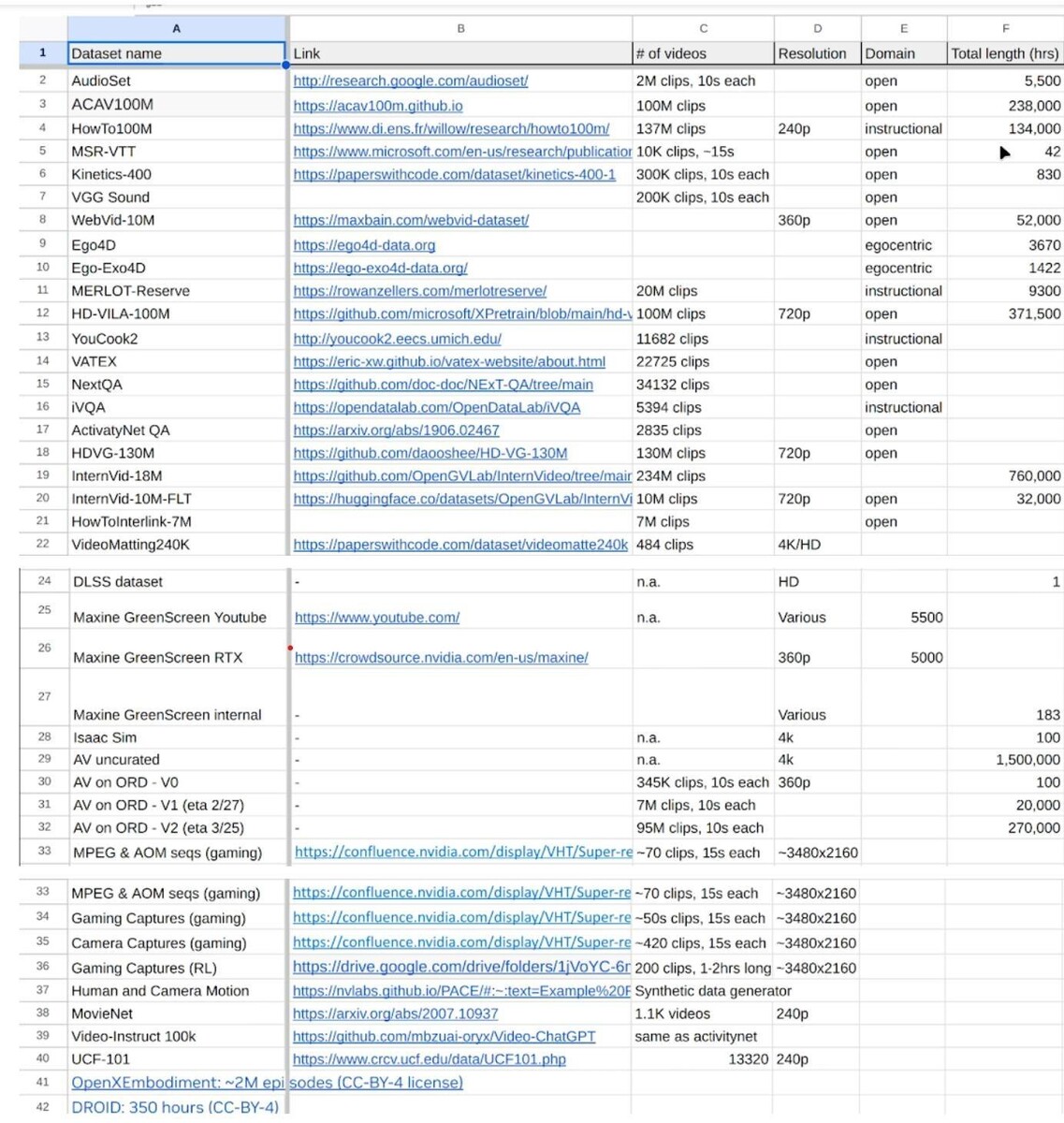
Wykorzystanie danych chronionych prawem autorskim do trenowania modeli sztucznej inteligencji jest nadal prawnie szarą strefą. Publiczne zbiory danych, takie jak InternVid-10M, HD-VG-130Mi inne oparte na milionach filmów z YouTube istnieją, ale są one przeznaczone wyłącznie do badań akademickich, a nie do celów komercyjnych. Chociaż Nvidia zatrudnia badaczy akademickich, ich wyniki ostatecznie trafią do produktów komercyjnych.
Na stronie pojawiło się kilka przepisów które narzucają standardy przejrzystości i wymagają od firm pracujących nad podstawowymi modelami sztucznej inteligencji współpracy z FTC i urzędem ds. praw autorskich. Jednak firmy niekoniecznie ujawniają swoje źródłowe zbiory danych, co znacznie utrudnia audyt.
Ponieważ główne firmy zajmujące się sztuczną inteligencją nadal kładą ręce na wszystkich dostępnych publicznie danych, aby trenować bardziej efektywne modele, zmiany legislacyjne są pilnie potrzebne, aby zapewnić bezpieczeństwo konsumentów i chronić własność intelektualną twórców.
W ubiegłym roku The New York Times pozwał OpenAI i Microsoft za nieautoryzowane wykorzystanie artykułów chronionych prawem autorskim do trenowania modeli sztucznej inteligencji. W maju artyści wizualni złożyli pozew przeciwko Stability AI, Midjourney, DeviantArt i Runway AI za wykorzystywanie kopii ich prac do trenowania modeli sztucznej inteligencji bez pozwolenia.
YouTube okazuje się być kopalnią danych dla firm zajmujących się sztuczną inteligencją. Niedawno Wired poinformował że największe firmy, w tym Apple, Nvidia, Anthropic i Salesforce, zeskrobały napisy ze 173 536 filmów na YouTube z ponad 48 000 kanałów, aby trenować swoją sztuczną inteligencję.
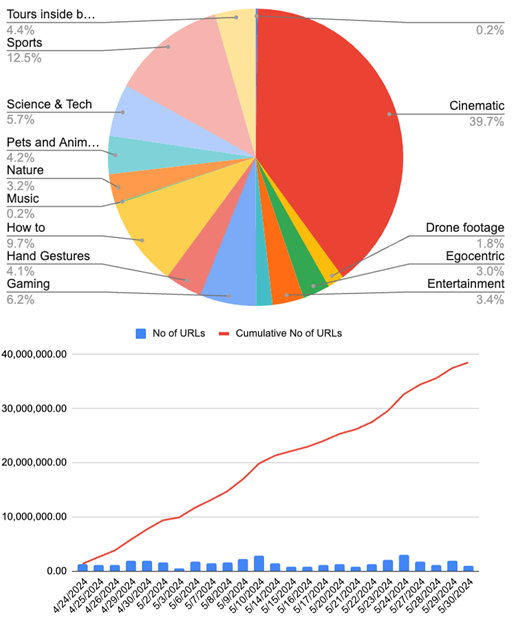
Do końca maja pracownicy Nvidii ogłosili wewnętrznie, że skompilowali 38,5 miliona adresów URL filmów, z których większość to treści kinowe. Inżynierowie dodali również zbiory danych, takie jak Ego-Exo4D, Ego4D, HOI4Doraz dane gier z GeForce Now.
Podczas gdy Ego-Exo4D i Ego4D mogą być licencjonowane zarówno do użytku akademickiego, jak i komercyjnego, HOI4D jest rozpowszechniany na licencji CC BY-NC, która wyraźnie zabrania użytku komercyjnego.
Zespół obecnie trenuje model 1B, każdy z 16 węzłami, z planami skalowania go do 10B.
Nvidia powiedziała 404 Media za pośrednictwem poczty elektronicznej:"nasze modele i nasze wysiłki badawcze są w pełni zgodne z literą i duchem prawa autorskiego"
Tymczasem dyrektor generalny Nvidii, Jensen Huang, wydaje się być zadowolony z postępów poczynionych przez jego pracowników.
Podobno wykrzyknął: "Świetna aktualizacja. Wiele firm musi budować wideo FM [modele fundamentalne]. My możemy zaoferować w pełni przyspieszony potok"
SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels of company despite staff legal/ethical concerns:https://t.co/DydXOyffUQ
— Jason Koebler (@jason_koebler) August 5, 2024
Źródło(a)
404 Media (wymaga rejestracji)














