

Wzrosty wydajności w benchmarkach generacji RTX 5090 i RTX 5080 zostały porównywalnie przyćmione przez serię GeForce 40 w PassMark

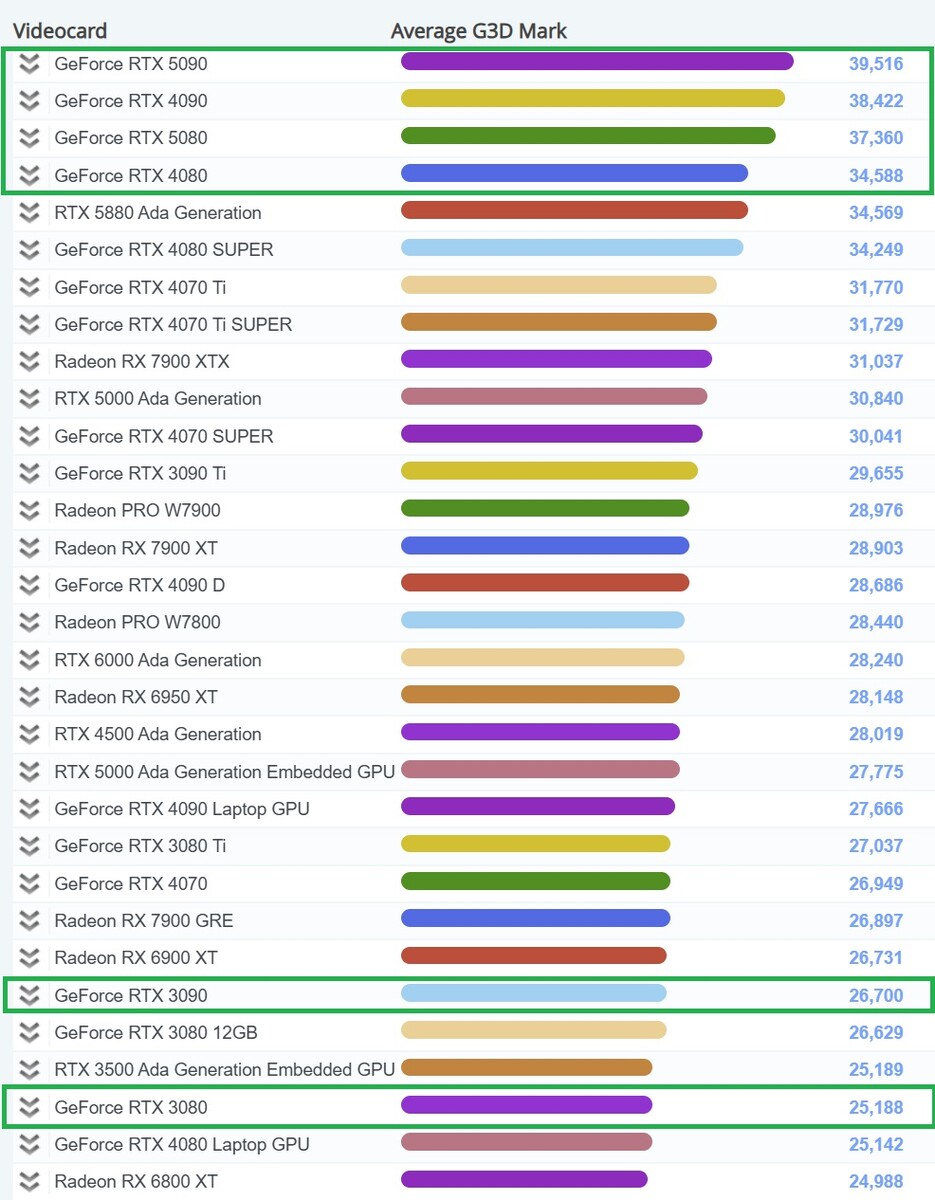
Należy od razu zaznaczyć, że wyniki te pochodzą z pojedynczego benchmarku i niekoniecznie reprezentują ogólną wydajność GeForce RTX 5090 i RTX 5080. Jak można się było spodziewać, Nvidia GeForce RTX 5090 zajęła obecnie pierwsze miejsce https://www.videocardbenchmark.net/high_end_gpus.html w rankingu kart graficznych PassMark (G3D Mark).
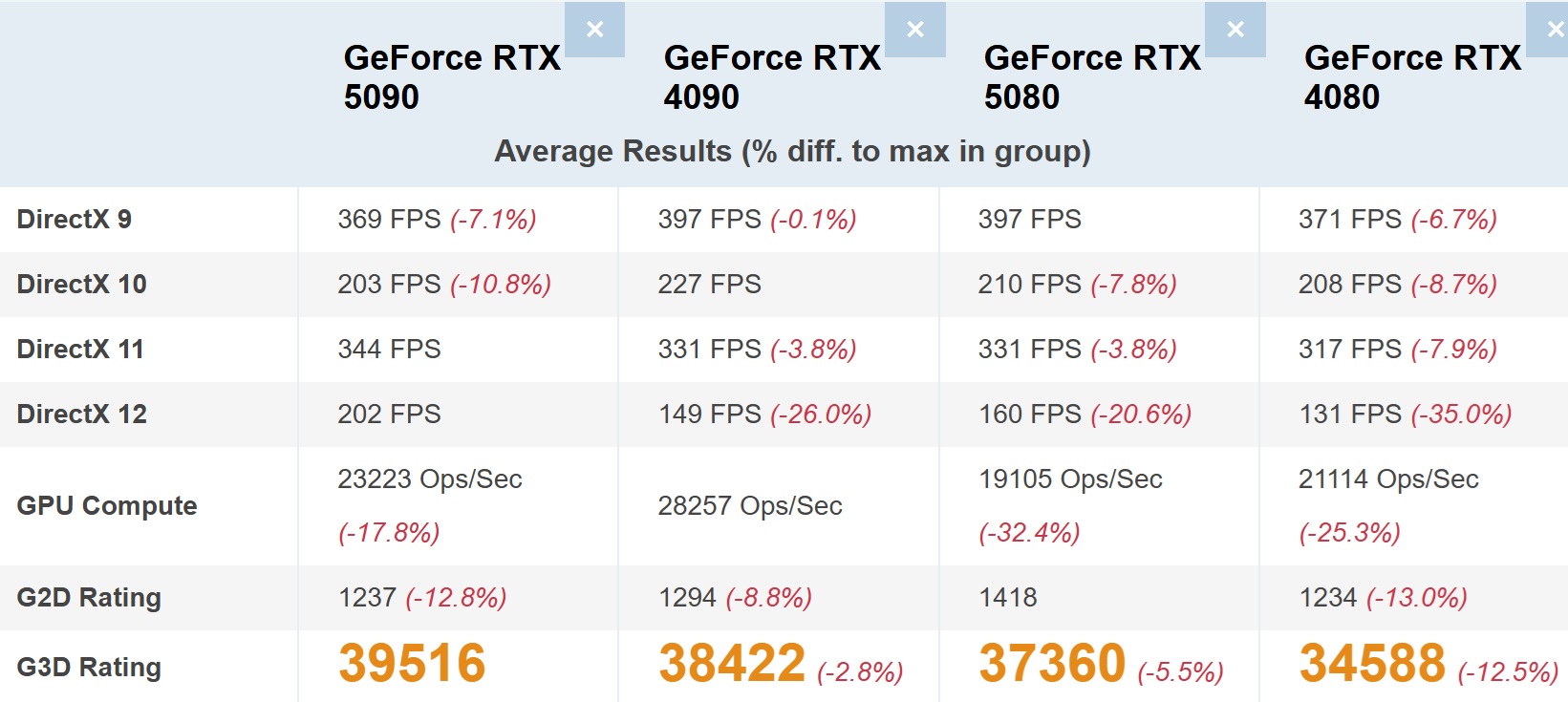
Sprzęt został dokładnie przetestowany, z pomiarami wydajności FPS w DirectX 9, DirectX 10, DirectX 11 i DirectX 12, podczas gdy w zestawie testowym znajduje się również benchmark GPU Compute. RTX 5090 uzyskał ocenę G3D na poziomie 39,516, dzięki czemu znalazł się na szczycie tabeli, a tuż za nim uplasował się model RTX 4090rTX 5080 i RTX 4080. Na pierwszy rzut oka wszystko wygląda dobrze.
Ale bliżej analiza pokazuje, że wzrost wydajności z jednej generacji na drugą jest daleki od zrównoważenia pod względem oceny G3D:
RTX 4090 (38,422) - RTX 5090 (39,516): +2.85%
RTX 3090 (26,700) - RTX 4090 (38,422): +43.9%
RTX 4080 (34 588) - RTX 5080 (37 360): +8.01%
RTX 3080 (25,188) - RTX 4080 (34,588): +37.3%
Można argumentować, że dane te są wyrwane z kontekstu, że to tylko pojedynczy benchmark, a karty Blackwell i tak są naszpikowane nowymi i ulepszonymi technologiami, takimi jak rdzenie RT czwartej generacji, rdzenie Tensor piątej generacji, DLSS 4.0 Multi Frame Generation i pamięć GDDR7. Ten drugi argument można jednak odnieść do różnicy między kartami Ada Lovelace (GeForce seria 40) a kartami Kartami Ampere (GeForce seria 30). Dla przykładu, te pierwsze były również wyposażone w kolejne generacje rdzeni RT i Tensor.
Co ważne, RTX 4080 i RTX 4090 posiadały układy oparte na procesie technologicznym 4N firmy TSMC (należącym do rodziny 5 nm node), podczas gdy procesory RTX 3080 i RTX 3090 były wytwarzane w 8 nm procesie produkcyjnym firmy Samsung (opracowanym na bazie technologii 10 nm). Zupełnie nowe RTX 5090 i RTX 5080 są napędzane przez GPU, które wykorzystują zoptymalizowany wariant procesu 4N, znany jako 4NPktóry został opracowany dla Nvidii przez TSMC. Wygląda na to, że na pierwszy plan wysuwa się tutaj udoskonalenie, a nie surowa wydajność.
Więcej artykułów związanych z tym urządzeniem
NVIDIA GeForce RTX 5090 Founders Edition (GeForce RTX 5090 Desktop Rodzina)Powiązane artykuły












